

Vous avez appris les bases de Terraform — la syntaxe HCL, les commandes essentielles, les variables et les outputs. Il est maintenant temps de passer à la pratique et de déployer une infrastructure réelle sur AWS. Dans cet article, nous allons construire pas à pas une infrastructure complète : un VPC avec ses sous-réseaux, une instance EC2 accessible depuis Internet, un bucket S3, et tous les composants réseau nécessaires pour que l'ensemble fonctionne.
Cet exercice vous permettra de comprendre comment les ressources Terraform interagissent entre elles, comment gérer les dépendances, et comment utiliser les data sources pour interroger des données existantes chez votre provider cloud. À la fin de cet article, vous disposerez d'une infrastructure AWS fonctionnelle, entièrement décrite en code.
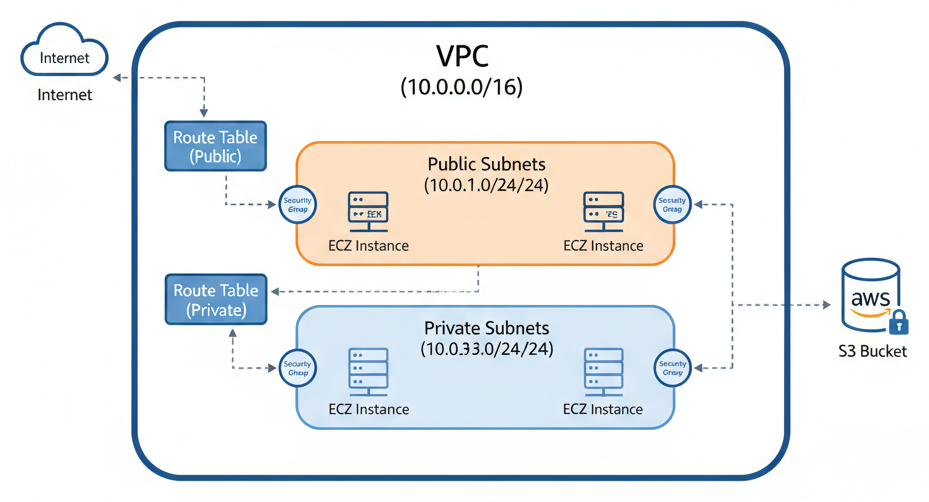
Architecture VPC AWS
Prérequis et Configuration du Provider AWS
Installer et configurer l'AWS CLI
Avant de commencer, assurez-vous que vous disposez d'un compte AWS et que l'AWS CLI est installé et configuré sur votre machine :
# Installer l'AWS CLI (macOS avec Homebrew)
brew install awscli
# Configurer vos identifiants
aws configure
# AWS Access Key ID: AKIA...
# AWS Secret Access Key: ****
# Default region name: eu-west-3
# Default output format: json
# Vérifier la configuration
aws sts get-caller-identity
Terraform utilisera ces identifiants pour interagir avec l'API AWS. En production, on préférera des mécanismes plus robustes comme les rôles IAM ou les profils d'instance, mais pour commencer, la configuration CLI suffit amplement.
Configurer le provider AWS dans Terraform
Créez la structure de votre projet :
mkdir -p ~/terraform-aws-demo
cd ~/terraform-aws-demo
Commencez par le fichier versions.tf pour déclarer les versions requises :
# versions.tf
terraform {
required_version = ">= 1.3.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
Puis le fichier providers.tf pour configurer le provider :
# providers.tf
provider "aws" {
region = var.region
default_tags {
tags = {
Project = var.project_name
Environment = var.environment
ManagedBy = "terraform"
}
}
}
L'attribut default_tags est extrêmement pratique : il applique automatiquement ces tags à toutes les ressources AWS créées par ce provider, sans avoir à les répéter dans chaque bloc resource.
Déclarer les variables du projet
# variables.tf
variable "project_name" {
description = "Nom du projet"
type = string
default = "terraform-demo"
}
variable "environment" {
description = "Environnement de déploiement"
type = string
default = "dev"
validation {
condition = contains(["dev", "staging", "prod"], var.environment)
error_message = "L'environnement doit être dev, staging ou prod."
}
}
variable "region" {
description = "Région AWS"
type = string
default = "eu-west-3"
}
variable "vpc_cidr" {
description = "Bloc CIDR du VPC"
type = string
default = "10.0.0.0/16"
}
variable "instance_type" {
description = "Type d'instance EC2"
type = string
default = "t3.micro"
}
variable "my_ip" {
description = "Votre adresse IP publique pour l'accès SSH (format CIDR)"
type = string
default = "0.0.0.0/0"
}
Initialisez le projet avec terraform init pour télécharger le provider AWS :
terraform init
Créer un VPC Complet
Le VPC (Virtual Private Cloud) est le réseau virtuel isolé dans lequel vivront toutes vos ressources. C'est la fondation de toute infrastructure AWS. Nous allons créer un VPC complet avec des sous-réseaux publics, une passerelle Internet et des tables de routage.
Le VPC principal
# network.tf
# Variables locales pour le réseau
locals {
azs = ["${var.region}a", "${var.region}b"]
public_subnets = ["10.0.1.0/24", "10.0.2.0/24"]
name_prefix = "${var.project_name}-${var.environment}"
}
# Création du VPC
resource "aws_vpc" "main" {
cidr_block = var.vpc_cidr
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "${local.name_prefix}-vpc"
}
}
Le VPC définit l'espace d'adressage IP global (10.0.0.0/16 = 65 536 adresses). Les options DNS sont importantes : enable_dns_hostnames attribue des noms DNS aux instances, et enable_dns_support active la résolution DNS dans le VPC.
Les sous-réseaux publics
Les sous-réseaux (subnets) découpent le VPC en segments plus petits, répartis sur plusieurs zones de disponibilité pour la haute disponibilité :
# Sous-réseaux publics
resource "aws_subnet" "public" {
count = length(local.public_subnets)
vpc_id = aws_vpc.main.id
cidr_block = local.public_subnets[count.index]
availability_zone = local.azs[count.index]
map_public_ip_on_launch = true
tags = {
Name = "${local.name_prefix}-public-${local.azs[count.index]}"
Tier = "public"
}
}
Remarquez l'utilisation de count pour créer plusieurs sous-réseaux à partir d'une liste. L'attribut map_public_ip_on_launch = true fait en sorte que chaque instance lancée dans ce sous-réseau reçoive automatiquement une adresse IP publique.
La passerelle Internet (Internet Gateway)
Un sous-réseau n'est réellement "public" que s'il a une route vers Internet. La passerelle Internet est le pont entre votre VPC et le réseau public :
# Passerelle Internet
resource "aws_internet_gateway" "main" {
vpc_id = aws_vpc.main.id
tags = {
Name = "${local.name_prefix}-igw"
}
}
Les tables de routage
La table de routage définit où envoyer le trafic réseau. Pour un sous-réseau public, tout le trafic non local doit être dirigé vers l'Internet Gateway :
# Table de routage publique
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.main.id
}
tags = {
Name = "${local.name_prefix}-public-rt"
}
}
# Association des sous-réseaux publics à la table de routage
resource "aws_route_table_association" "public" {
count = length(aws_subnet.public)
subnet_id = aws_subnet.public[count.index].id
route_table_id = aws_route_table.public.id
}
La route 0.0.0.0/0 est la route par défaut : tout trafic qui ne correspond pas à une route plus spécifique sera envoyé vers l'Internet Gateway. L'association lie chaque sous-réseau à cette table de routage.
Voici une vue d'ensemble de l'architecture réseau que nous venons de créer :
┌─────────────────────────────────────────────┐
│ VPC (10.0.0.0/16) │
│ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Subnet Public│ │ Subnet Public│ │
│ │ 10.0.1.0/24 │ │ 10.0.2.0/24 │ │
│ │ (AZ: a) │ │ (AZ: b) │ │
│ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │
│ └─────────┬─────────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ Route Table │ │
│ │ 0.0.0.0/0→IGW │ │
│ └────────┬────────┘ │
│ │ │
│ ┌────────┴────────┐ │
│ │ Internet Gateway│ │
│ └────────┬────────┘ │
└───────────────────┼─────────────────────────┘
│
Internet
Déployer une Instance EC2
Trouver la bonne AMI avec un Data Source
Plutôt que de coder en dur l'identifiant d'une AMI (qui change d'une région à l'autre et au fil du temps), nous utilisons un data source pour rechercher dynamiquement la dernière AMI Amazon Linux 2023 :
# compute.tf
# Rechercher la dernière AMI Amazon Linux 2023
data "aws_ami" "amazon_linux" {
most_recent = true
owners = ["amazon"]
filter {
name = "name"
values = ["al2023-ami-*-x86_64"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
filter {
name = "root-device-type"
values = ["ebs"]
}
}
Un data source (préfixé par data) ne crée rien : il interroge l'API AWS pour récupérer des informations sur des ressources existantes. Ici, il trouve la dernière AMI correspondant à nos critères. Vous pouvez ensuite référencer l'ID de l'AMI avec data.aws_ami.amazon_linux.id.
Créer un Security Group
Le security group fait office de pare-feu virtuel pour votre instance. Nous allons autoriser le trafic SSH (port 22), HTTP (port 80) en entrée, et tout le trafic en sortie :
# Security Group pour l'instance web
resource "aws_security_group" "web" {
name_prefix = "${local.name_prefix}-web-"
description = "Security group pour le serveur web"
vpc_id = aws_vpc.main.id
# Règle SSH
ingress {
description = "SSH depuis mon IP"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = [var.my_ip]
}
# Règle HTTP
ingress {
description = "HTTP depuis partout"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Règle HTTPS
ingress {
description = "HTTPS depuis partout"
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Tout le trafic sortant autorisé
egress {
description = "Tout le trafic sortant"
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "${local.name_prefix}-web-sg"
}
lifecycle {
create_before_destroy = true
}
}
Remarquez le bloc lifecycle avec create_before_destroy = true. C'est une bonne pratique pour les security groups : lors d'une modification, Terraform crée d'abord le nouveau SG avant de supprimer l'ancien, évitant ainsi une interruption de service.
Générer une paire de clés SSH
Pour accéder à votre instance en SSH, vous avez besoin d'une paire de clés. Vous pouvez soit en importer une existante, soit en générer une avec Terraform :
# Générer une clé SSH avec Terraform
resource "tls_private_key" "ssh" {
algorithm = "RSA"
rsa_bits = 4096
}
# Enregistrer la clé publique dans AWS
resource "aws_key_pair" "main" {
key_name = "${local.name_prefix}-key"
public_key = tls_private_key.ssh.public_key_openssh
tags = {
Name = "${local.name_prefix}-key"
}
}
# Sauvegarder la clé privée localement
resource "local_file" "ssh_private_key" {
content = tls_private_key.ssh.private_key_pem
filename = "${path.module}/${local.name_prefix}-key.pem"
file_permission = "0400"
}
N'oubliez pas d'ajouter le provider tls dans votre fichier versions.tf :
# Ajoutez ceci dans le bloc required_providers de versions.tf
tls = {
source = "hashicorp/tls"
version = "~> 4.0"
}
local = {
source = "hashicorp/local"
version = "~> 2.0"
}
Lancer l'instance EC2
Nous avons maintenant tous les éléments pour déployer notre instance EC2 :
# Instance EC2
resource "aws_instance" "web" {
ami = data.aws_ami.amazon_linux.id
instance_type = var.instance_type
key_name = aws_key_pair.main.key_name
subnet_id = aws_subnet.public[0].id
vpc_security_group_ids = [aws_security_group.web.id]
root_block_device {
volume_size = 20
volume_type = "gp3"
encrypted = true
tags = {
Name = "${local.name_prefix}-web-root"
}
}
user_data = <<-EOF
#!/bin/bash
yum update -y
yum install -y httpd
systemctl start httpd
systemctl enable httpd
# Page d'accueil personnalisée
cat > /var/www/html/index.html <<'HTML'
<!DOCTYPE html>
<html>
<head><title>Terraform Demo</title></head>
<body>
<h1>Infrastructure déployée avec Terraform</h1>
<p>Cette page est servie depuis une instance EC2 dans le VPC créé par Terraform.</p>
<p>Région: eu-west-3 (Paris)</p>
</body>
</html>
HTML
EOF
tags = {
Name = "${local.name_prefix}-web"
Role = "web-server"
}
}
Décortiquons les points importants :
- ami : référence le data source pour obtenir dynamiquement la dernière AMI.
- subnet_id : place l'instance dans le premier sous-réseau public. Notez la syntaxe
aws_subnet.public[0].idqui référence le premier élément de la liste de sous-réseaux créés aveccount. - vpc_security_group_ids : attache notre security group à l'instance.
- root_block_device : configure le disque racine avec le chiffrement activé.
- user_data : un script bash exécuté au premier démarrage de l'instance. Ici, il installe et configure Apache.
Créer un Bucket S3
Amazon S3 est le service de stockage objet d'AWS. Créons un bucket avec les bonnes pratiques de sécurité :
# storage.tf
# Bucket S3
resource "aws_s3_bucket" "assets" {
bucket = "${local.name_prefix}-assets-${data.aws_caller_identity.current.account_id}"
tags = {
Name = "${local.name_prefix}-assets"
}
}
# Récupérer l'ID du compte AWS courant
data "aws_caller_identity" "current" {}
# Versionning du bucket
resource "aws_s3_bucket_versioning" "assets" {
bucket = aws_s3_bucket.assets.id
versioning_configuration {
status = "Enabled"
}
}
# Chiffrement côté serveur
resource "aws_s3_bucket_server_side_encryption_configuration" "assets" {
bucket = aws_s3_bucket.assets.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
bucket_key_enabled = true
}
}
# Bloquer tout accès public
resource "aws_s3_bucket_public_access_block" "assets" {
bucket = aws_s3_bucket.assets.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
# Politique de cycle de vie
resource "aws_s3_bucket_lifecycle_configuration" "assets" {
bucket = aws_s3_bucket.assets.id
rule {
id = "archive-old-versions"
status = "Enabled"
noncurrent_version_transition {
noncurrent_days = 30
storage_class = "STANDARD_IA"
}
noncurrent_version_transition {
noncurrent_days = 90
storage_class = "GLACIER"
}
noncurrent_version_expiration {
noncurrent_days = 365
}
}
}
Notez que depuis AWS Provider v4, la configuration S3 est découpée en ressources séparées (versioning, encryption, lifecycle, etc.) plutôt que d'être regroupée dans le bloc aws_s3_bucket. Cette approche est plus modulaire et permet de gérer chaque aspect indépendamment.
Le data source aws_caller_identity récupère l'identifiant de votre compte AWS. Nous l'utilisons dans le nom du bucket pour garantir son unicité globale (les noms de buckets S3 sont uniques au niveau mondial).
Gérer les Dépendances entre Ressources
Références implicites
Dans la plupart des cas, Terraform détecte automatiquement les dépendances entre ressources grâce aux références implicites. Quand vous écrivez vpc_id = aws_vpc.main.id dans un sous-réseau, Terraform comprend que le sous-réseau dépend du VPC et les crée dans le bon ordre :
# Dépendance implicite : le subnet dépend du VPC
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id # ← référence implicite au VPC
cidr_block = "10.0.1.0/24"
}
# Dépendance implicite : l'instance dépend du subnet et du SG
resource "aws_instance" "web" {
subnet_id = aws_subnet.public[0].id # ← dépend du subnet
vpc_security_group_ids = [aws_security_group.web.id] # ← dépend du SG
key_name = aws_key_pair.main.key_name # ← dépend de la key pair
}
Terraform construit un graphe de dépendances (DAG — Directed Acyclic Graph) à partir de ces références et détermine l'ordre optimal de création. Les ressources sans dépendances mutuelles sont créées en parallèle pour accélérer le déploiement.
Vous pouvez visualiser ce graphe avec :
terraform graph | dot -Tpng > graph.png
Dépendances explicites avec depends_on
Parfois, une dépendance existe mais n'est pas visible dans les attributs de la ressource. Dans ce cas, utilisez depends_on pour la déclarer explicitement :
# L'instance a besoin que la route vers Internet soit en place
# avant de pouvoir télécharger des paquets via user_data
resource "aws_instance" "web" {
ami = data.aws_ami.amazon_linux.id
instance_type = var.instance_type
subnet_id = aws_subnet.public[0].id
user_data = <<-EOF
#!/bin/bash
yum update -y
yum install -y httpd
EOF
# Dépendance explicite : s'assurer que la route Internet
# est configurée avant de lancer l'instance
depends_on = [
aws_route_table_association.public,
aws_internet_gateway.main
]
tags = {
Name = "${local.name_prefix}-web"
}
}
Utilisez depends_on avec parcimonie. Dans la grande majorité des cas, les références implicites suffisent. L'usage excessif de depends_on rend le code plus difficile à maintenir et peut ralentir les déploiements en ajoutant des contraintes d'ordonnancement inutiles.
Les Outputs de notre Infrastructure
Définissons les outputs pour pouvoir exploiter facilement notre infrastructure après le déploiement :
# outputs.tf
output "vpc_id" {
description = "ID du VPC"
value = aws_vpc.main.id
}
output "public_subnet_ids" {
description = "IDs des sous-réseaux publics"
value = aws_subnet.public[*].id
}
output "instance_id" {
description = "ID de l'instance EC2"
value = aws_instance.web.id
}
output "instance_public_ip" {
description = "Adresse IP publique de l'instance"
value = aws_instance.web.public_ip
}
output "instance_public_dns" {
description = "Nom DNS public de l'instance"
value = aws_instance.web.public_dns
}
output "website_url" {
description = "URL du site web"
value = "http://${aws_instance.web.public_ip}"
}
output "ssh_command" {
description = "Commande SSH pour se connecter à l'instance"
value = "ssh -i ${local_file.ssh_private_key.filename} ec2-user@${aws_instance.web.public_ip}"
}
output "s3_bucket_name" {
description = "Nom du bucket S3"
value = aws_s3_bucket.assets.bucket
}
output "s3_bucket_arn" {
description = "ARN du bucket S3"
value = aws_s3_bucket.assets.arn
}
output "ami_used" {
description = "AMI utilisée pour l'instance"
value = {
id = data.aws_ami.amazon_linux.id
name = data.aws_ami.amazon_linux.name
}
}
Déployer et Vérifier l'Infrastructure
Planifier le déploiement
# Initialiser (si pas encore fait)
terraform init
# Valider la syntaxe
terraform validate
# Voir le plan d'exécution
terraform plan
Le terraform plan affiche une sortie détaillée montrant toutes les ressources qui seront créées. Prenez le temps de la lire attentivement avant d'appliquer :
Plan: 14 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ ami_used = {
+ id = "ami-0abc123..."
+ name = "al2023-ami-2023.1.20230725.0-kernel-6.1-x86_64"
}
+ instance_public_ip = (known after apply)
+ s3_bucket_name = "terraform-demo-dev-assets-123456789012"
+ ssh_command = (known after apply)
+ vpc_id = (known after apply)
+ website_url = (known after apply)
Appliquer le déploiement
# Déployer l'infrastructure
terraform apply
# Ou déployer sans confirmation interactive
terraform apply -auto-approve
Après quelques minutes, Terraform affiche les outputs. Vous pouvez alors vérifier que tout fonctionne :
# Récupérer l'IP publique
terraform output instance_public_ip
# Tester le serveur web
curl $(terraform output -raw website_url)
# Se connecter en SSH
eval $(terraform output -raw ssh_command)
Explorer les ressources créées
# Lister toutes les ressources gérées par Terraform
terraform state list
# Résultat attendu :
# aws_instance.web
# aws_internet_gateway.main
# aws_key_pair.main
# aws_route_table.public
# aws_route_table_association.public[0]
# aws_route_table_association.public[1]
# aws_s3_bucket.assets
# aws_s3_bucket_public_access_block.assets
# aws_s3_bucket_server_side_encryption_configuration.assets
# aws_s3_bucket_versioning.assets
# aws_security_group.web
# aws_subnet.public[0]
# aws_subnet.public[1]
# aws_vpc.main
# local_file.ssh_private_key
# tls_private_key.ssh
# Inspecter une ressource spécifique
terraform state show aws_instance.web
Nettoyer l'Infrastructure
L'un des avantages majeurs de Terraform est la capacité de détruire proprement toute l'infrastructure. C'est indispensable pour éviter les coûts inutiles en développement et pour les environnements éphémères :
# Voir ce qui sera détruit
terraform plan -destroy
# Détruire toute l'infrastructure
terraform destroy
Terraform supprime les ressources dans l'ordre inverse de leur création, en respectant les dépendances. Le VPC sera détruit en dernier, après que tous les sous-réseaux, security groups et instances qu'il contient aient été supprimés.
Récapitulatif du Projet Complet
Voici la structure finale de notre projet :
terraform-aws-demo/
├── versions.tf # Versions Terraform et providers
├── providers.tf # Configuration du provider AWS
├── variables.tf # Variables d'entrée
├── locals.tf # (optionnel) Variables locales
├── network.tf # VPC, subnets, IGW, routes
├── compute.tf # EC2, security groups, key pairs
├── storage.tf # S3 bucket et configuration
├── outputs.tf # Valeurs de sortie
└── terraform.tfvars # Valeurs des variables
Cette organisation en fichiers thématiques est une convention de la communauté Terraform. Chaque fichier a une responsabilité claire, ce qui facilite la navigation et la maintenance.
Conclusion
Vous venez de déployer votre première infrastructure AWS complète avec Terraform. Récapitulons ce que nous avons appris :
- Configuration du provider AWS avec les default_tags pour une gestion cohérente des tags
- Création d'un VPC complet avec sous-réseaux, Internet Gateway et tables de routage
- Déploiement d'une instance EC2 avec security group, clé SSH et user_data
- Création d'un bucket S3 sécurisé avec versioning, chiffrement et blocage d'accès public
- Data sources pour interroger des données existantes (AMI, identité du compte)
- Gestion des dépendances implicites et explicites entre ressources
Cette infrastructure est fonctionnelle mais reste simple. En production, vous ajouteriez des sous-réseaux privés, une NAT Gateway, un Load Balancer, un Auto Scaling Group, et bien d'autres composants. Mais les fondations sont posées.
Dans le prochain article, nous aborderons un sujet critique : le Terraform State. Vous découvrirez comment Terraform suit l'état de votre infrastructure, pourquoi c'est essentiel, et comment configurer un backend distant pour travailler en équipe. C'est un sujet incontournable pour passer de l'expérimentation au déploiement professionnel.





