
Introduction
Le noyau Linux est au cœur de l'infrastructure informatique mondiale. Des serveurs de production aux clusters Kubernetes, en passant par les smartphones Android, il orchestre des milliards d'opérations chaque seconde. Pourtant, pendant des décennies, observer ce qui se passait à l'intérieur du kernel ou y ajouter de la logique personnalisée nécessitait soit de modifier le code source du noyau, soit de charger des modules kernel — deux opérations risquées, complexes et lentes à déployer.
eBPF (extended Berkeley Packet Filter) a changé la donne. Cette technologie révolutionnaire permet d'exécuter des programmes sandboxés directement dans le noyau Linux, sans modifier son code source ni charger de modules. Elle a ouvert la voie à une nouvelle génération d'outils d'observabilité, de networking et de sécurité qui redéfinissent ce qui est possible sous Linux.
Architecture en un coup d'œil
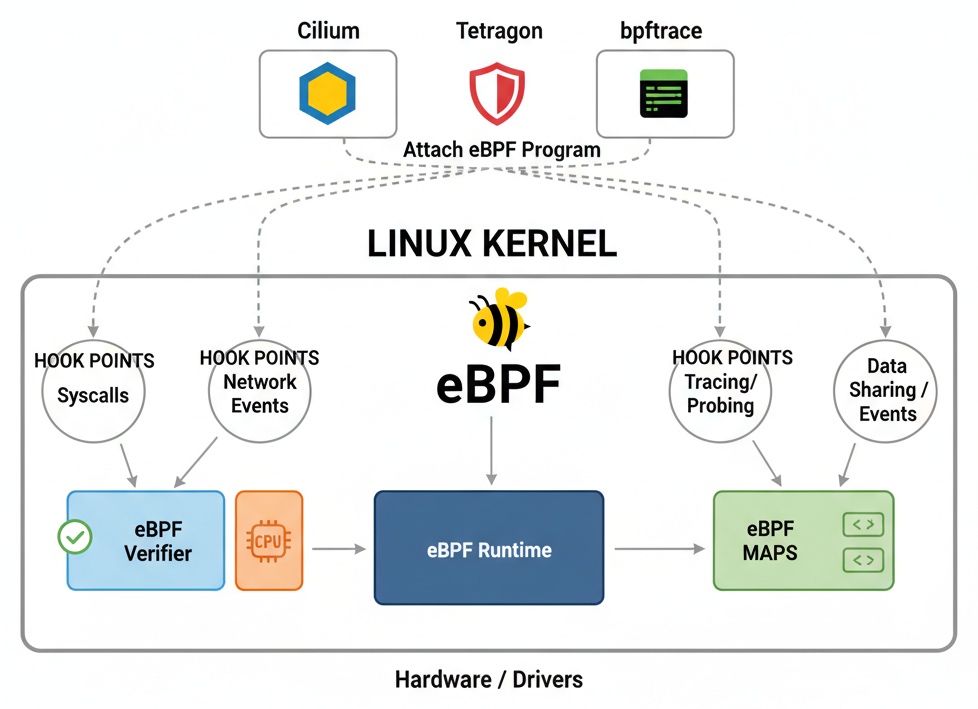
En 2025-2026, eBPF est devenu un pilier incontournable de l'infrastructure cloud native. Des géants comme Meta, Google, Netflix, Cloudflare, Microsoft et Apple l'utilisent massivement en production. Des projets comme Cilium, Falco, Tetragon et Pixie ont construit des solutions complètes sur cette fondation.
Dans cet article, nous allons explorer en profondeur ce qu'est eBPF, comment il fonctionne, ses cas d'usage majeurs, les outils qui en tirent parti, et comment vous pouvez commencer à l'utiliser dès aujourd'hui.
Qu'est-ce qu'eBPF ? Un peu d'histoire
Du BPF classique à eBPF
L'histoire commence en 1992 avec le Berkeley Packet Filter (BPF), conçu par Steven McCanne et Van Jacobson au Lawrence Berkeley National Laboratory. Le BPF classique était une machine virtuelle minimaliste dans le noyau, conçue pour un seul objectif : filtrer efficacement les paquets réseau. C'est la technologie sous-jacente de tcpdump — quand vous écrivez tcpdump port 80, cette expression est compilée en bytecode BPF et exécutée dans le kernel pour filtrer les paquets directement à la source.
Le BPF classique était limité : registres 32 bits, jeu d'instructions restreint, pas de possibilité de stocker des données entre les exécutions, et uniquement orienté réseau. Mais l'idée fondamentale — exécuter du code utilisateur de manière sûre dans le kernel — était brillante.
En 2014, Alexei Starovoitov, ingénieur chez PLUMgrid (puis Facebook/Meta), a proposé une refonte majeure du BPF dans le noyau Linux. Cette version étendue — eBPF — a été progressivement intégrée à partir du kernel 3.15 puis massivement enrichie dans les versions suivantes :
- Kernel 3.15 (2014) : introduction de la nouvelle machine virtuelle eBPF avec des registres 64 bits
- Kernel 4.1 (2015) : programmes eBPF attachables aux kprobes (traçage de fonctions kernel)
- Kernel 4.7 (2016) : support des programmes attachés au traffic control (networking)
- Kernel 4.10 (2017) : XDP (eXpress Data Path) pour le traitement réseau ultra-rapide
- Kernel 5.3 (2019) : BTF (BPF Type Format) pour la portabilité des programmes
- Kernel 5.8 (2020) : support des ring buffers, améliorations significatives
- Kernel 6.x (2022-2025) : maturité, nouveaux types de programmes, améliorations continues
Aujourd'hui, le terme « eBPF » est souvent simplifié en « BPF » dans la communauté. La Fondation eBPF, hébergée par la Linux Foundation et soutenue par Meta, Google, Microsoft, Netflix et Isovalent, coordonne le développement de l'écosystème.
Pourquoi eBPF est-il révolutionnaire ?
Pour comprendre l'impact d'eBPF, il faut comprendre le problème qu'il résout. Traditionnellement, pour ajouter une fonctionnalité au noyau Linux, vous aviez trois options :
- Modifier le code source du noyau : processus long (proposer un patch, review, acceptation, attendre la prochaine release, distribution par les distros). Délai : mois voire années.
- Charger un module kernel : plus rapide, mais risqué (un bug dans un module = kernel panic), pas de sandboxing, difficile à maintenir entre versions du kernel.
- Utiliser les interfaces existantes : limitées à ce que le kernel expose (procfs, sysfs, netfilter, etc.).
eBPF introduit une quatrième voie : programmer le kernel de manière sûre et dynamique. Les programmes eBPF sont vérifiés avant exécution, exécutés dans un sandbox, et peuvent être chargés et déchargés à chaud sans redémarrage. C'est comme si JavaScript avait rendu le web programmable — eBPF rend le kernel programmable.
Comment fonctionne eBPF en profondeur
Architecture de la machine virtuelle eBPF
eBPF est fondamentalement une machine virtuelle in-kernel avec les caractéristiques suivantes :
- 11 registres 64 bits (r0-r10) : r0 pour la valeur de retour, r1-r5 pour les arguments de fonctions, r6-r9 préservés entre appels, r10 pour le pointeur de pile (lecture seule)
- Jeu d'instructions RISC : environ 100 instructions couvrant l'arithmétique, les sauts, les accès mémoire et les appels de fonctions
- Pile de 512 octets : limitation volontaire pour la sécurité
- Pas de boucles infinies garanties : le vérifieur s'assure que chaque programme termine
Le vérifieur (verifier) : la clé de la sécurité
Le composant le plus critique d'eBPF est son vérifieur statique. Avant qu'un programme eBPF ne soit autorisé à s'exécuter dans le kernel, il passe par une analyse exhaustive :
- Analyse de flux de contrôle : vérifie que le programme est un DAG (Directed Acyclic Graph) — pas de boucles infinies possibles (les boucles bornées sont autorisées depuis le kernel 5.3)
- Vérification des accès mémoire : chaque lecture/écriture est validée pour s'assurer qu'elle reste dans les bornes autorisées
- Suivi des types : chaque registre est typé et les opérations invalides sont rejetées
- Vérification de terminaison : le programme doit terminer en un nombre borné d'instructions (limite actuelle : 1 million d'instructions vérifiées)
- Vérification des helper functions : seules les fonctions d'aide autorisées pour le type de programme peuvent être appelées
Si le vérifieur rejette un programme, il fournit un message d'erreur détaillé expliquant pourquoi. Ce mécanisme garantit qu'un programme eBPF ne peut pas crasher le kernel, ne peut pas accéder à de la mémoire arbitraire, et terminera toujours.
Compilation JIT (Just-In-Time)
Une fois vérifié, le bytecode eBPF est compilé en code machine natif par le compilateur JIT du kernel. Cela signifie que les programmes eBPF s'exécutent à des performances proches du code natif, sans overhead d'interprétation. Le JIT est disponible pour toutes les architectures majeures : x86_64, ARM64, RISC-V, s390x, etc.
Les maps eBPF : le stockage partagé
Les maps sont des structures de données clé-valeur qui permettent de stocker des données entre les exécutions de programmes eBPF et de partager des données entre le kernel et l'espace utilisateur. Les types de maps incluent :
- Hash maps : tables de hachage classiques
- Array maps : tableaux indexés
- Ring buffers : pour le streaming d'événements vers l'espace utilisateur
- LRU maps : avec éviction automatique des entrées les moins récemment utilisées
- Per-CPU maps : une instance par CPU pour éviter le verrouillage
- Stack trace maps : pour capturer des traces d'appels
- Map-in-map : maps imbriquées pour des structures complexes
Points d'attache (hook points)
Les programmes eBPF peuvent être attachés à de nombreux points du kernel :
- kprobes / kretprobes : entrée et sortie de n'importe quelle fonction du kernel
- tracepoints : points de traçage statiques définis dans le kernel
- uprobes / uretprobes : entrée et sortie de fonctions en espace utilisateur
- XDP (eXpress Data Path) : traitement des paquets réseau avant même la pile réseau
- TC (Traffic Control) : filtrage et manipulation du trafic réseau
- Socket filters : filtrage au niveau des sockets
- cgroup hooks : contrôle des opérations par cgroup (réseau, device, etc.)
- LSM (Linux Security Modules) : hooks de sécurité pour le contrôle d'accès
- Perf events : événements de performance matériels et logiciels
- fentry / fexit : variantes modernes des kprobes avec accès aux arguments typés
Cas d'usage majeurs d'eBPF
1. Observabilité et monitoring
L'observabilité est le cas d'usage originel et le plus mature d'eBPF. Au lieu de s'appuyer sur des mécanismes coûteux comme strace (qui utilise ptrace et a un overhead de 100x), eBPF permet de tracer n'importe quelle fonction du kernel ou de l'espace utilisateur avec un overhead quasi nul (typiquement moins de 1 %).
Voici ce que vous pouvez observer avec eBPF :
- Latence de chaque opération I/O disque (quel processus, quel fichier, combien de temps)
- Chaque connexion TCP ouverte/fermée avec sa durée de vie et ses métriques
- Chaque appel système avec ses arguments et sa valeur de retour
- Chaque ouverture de fichier, chaque allocation mémoire
- Les stack traces de n'importe quel événement
- Le profiling CPU continu avec un overhead minimal
2. Networking haute performance
eBPF a transformé le networking sous Linux. Avec XDP, les paquets peuvent être traités avant même d'entrer dans la pile réseau du kernel, permettant des performances de l'ordre de millions de paquets par seconde par cœur CPU. Les cas d'usage incluent :
- Load balancing : Facebook/Meta utilise eBPF (Katran) pour son load balancer L4, traitant des milliards de requêtes par jour
- DDoS mitigation : Cloudflare utilise XDP pour filtrer le trafic malveillant au plus tôt
- Service mesh : Cilium remplace les proxies sidecar avec du networking eBPF kernel-level
- Network policies : remplacement d'iptables par des programmes eBPF plus performants et plus expressifs
3. Sécurité runtime
eBPF permet une visibilité sans précédent sur le comportement des applications au runtime, ce qui en fait un outil puissant pour la détection d'intrusions et l'application de politiques de sécurité :
- Détection de comportements anormaux : exécution de binaires inattendus, ouverture de fichiers sensibles, connexions réseau suspectes
- Runtime enforcement : bloquer en temps réel des opérations dangereuses (pas seulement détecter, mais empêcher)
- Audit : tracer toutes les opérations privilégiées, les changements de capabilities, les appels système sensibles
- Forensics : capturer le contexte complet d'un incident (processus, fichiers, réseau, stack traces)
4. Profiling et optimisation des performances
eBPF est devenu l'outil de choix pour le profiling en production :
- Profiling CPU continu : identifier les fonctions les plus consommatrices sans overhead significatif
- Analyse de latence : mesurer précisément la latence de chaque couche (application, système de fichiers, bloc device, driver)
- Détection de contention : identifier les locks, les attentes I/O, les cache misses
- Analyse off-CPU : comprendre pourquoi un processus ne s'exécute pas (attentes I/O, locks, scheduling)
Les outils BCC : la boîte à outils du sysadmin moderne
BCC (BPF Compiler Collection) est une collection d'outils eBPF prêts à l'emploi, développée par Brendan Gregg (Netflix) et la communauté. Ces outils couvrent un large spectre de l'observabilité système. Voici les plus essentiels :
execsnoop : tracer chaque exécution de programme
execsnoop trace chaque appel à execve(), c'est-à-dire chaque fois qu'un nouveau programme est lancé sur le système. C'est inestimable pour comprendre ce qui se passe réellement sur un serveur :
# Installer BCC tools sur Ubuntu/Debian
sudo apt-get install bpfcc-tools linux-headers-$(uname -r)
# Sur Fedora/RHEL
sudo dnf install bcc-tools
# Tracer toutes les exécutions de programmes
sudo execsnoop-bpfcc
# Exemple de sortie :
# PCOMM PID PPID RET ARGS
# bash 18478 18477 0 /bin/bash
# curl 18479 18478 0 /usr/bin/curl -s https://api.example.com
# grep 18480 18478 0 /usr/bin/grep status
# node 18481 18476 0 /usr/bin/node /app/server.js
# Filtrer par nom de processus
sudo execsnoop-bpfcc -n curl
# Inclure les timestamps
sudo execsnoop-bpfcc -Tbiosnoop : tracer les I/O disque
biosnoop trace chaque opération d'entrée/sortie au niveau du block device, avec la latence précise :
# Tracer toutes les I/O disque
sudo biosnoop-bpfcc
# Exemple de sortie :
# TIME(s) COMM PID DISK T SECTOR BYTES LAT(ms)
# 0.000 postgres 1234 sda R 12345678 8192 0.42
# 0.001 postgres 1234 sda R 12345686 4096 0.38
# 0.015 jbd2/sda1 456 sda W 98765432 16384 1.23
# Filtrer par PID
sudo biosnoop-bpfcc -p 1234
# Filtrer par disque
sudo biosnoop-bpfcc -d sdatcplife : suivre le cycle de vie des connexions TCP
tcplife trace chaque connexion TCP de son ouverture à sa fermeture, avec la durée, les octets envoyés et reçus :
# Tracer toutes les connexions TCP
sudo tcplife-bpfcc
# Exemple de sortie :
# PID COMM LADDR LPORT RADDR RPORT TX_KB RX_KB MS
# 1234 curl 10.0.0.5 54312 93.184.216.34 443 1 12 250
# 5678 nginx 10.0.0.5 80 10.0.0.100 39482 145 2 30042
# 9012 postgres 10.0.0.5 5432 10.0.0.20 48210 512 128 5023
# Filtrer par port local
sudo tcplife-bpfcc -L 443
# Filtrer les connexions de plus d'1 seconde
sudo tcplife-bpfcc -D 1000opensnoop : tracer les ouvertures de fichiers
opensnoop trace chaque appel à open() et openat(), révélant quels fichiers chaque processus tente d'ouvrir :
# Tracer toutes les ouvertures de fichiers
sudo opensnoop-bpfcc
# Exemple de sortie :
# PID COMM FD ERR PATH
# 1234 python3 5 0 /app/config.yaml
# 1234 python3 6 0 /app/data/users.db
# 5678 nginx 12 0 /var/log/nginx/access.log
# 9012 bash -1 2 /etc/shadow # ENOENT ou permission denied
# Filtrer par PID
sudo opensnoop-bpfcc -p 1234
# Afficher seulement les erreurs (fichiers non trouvés, permissions refusées)
sudo opensnoop-bpfcc -xbpftrace : le langage de traçage eBPF
bpftrace est un langage de traçage haut niveau pour eBPF, inspiré d'AWK et de DTrace. Il permet d'écrire des programmes de traçage en une ligne ou en quelques lignes, sans avoir à écrire du C ou à utiliser les APIs eBPF bas niveau. C'est l'outil de prédilection pour l'exploration et le debugging en temps réel.
Installation de bpftrace
# Ubuntu/Debian (22.04+)
sudo apt-get install bpftrace
# Fedora
sudo dnf install bpftrace
# Arch Linux
sudo pacman -S bpftrace
# Vérifier l'installation
bpftrace --version
# bpftrace v0.21.0
# Lister les tracepoints disponibles
sudo bpftrace -l 'tracepoint:syscalls:*'
# Lister les kprobes disponibles
sudo bpftrace -l 'kprobe:tcp_*'Exemples pratiques bpftrace
# 1. Compter les appels système par nom
sudo bpftrace -e '
tracepoint:raw_syscalls:sys_enter {
@syscalls[comm] = count();
}
'
# 2. Histogramme de la latence des lectures disque
sudo bpftrace -e '
kprobe:blk_account_io_start { @start[arg0] = nsecs; }
kprobe:blk_account_io_done /@start[arg0]/ {
@usecs = hist((nsecs - @start[arg0]) / 1000);
delete(@start[arg0]);
}
'
# 3. Tracer les ouvertures de fichiers avec le chemin complet
sudo bpftrace -e '
tracepoint:syscalls:sys_enter_openat {
printf("%-6d %-16s %s\n", pid, comm, str(args.filename));
}
'
# 4. Top 10 des processus par appels système (sur 5 secondes)
sudo bpftrace -e '
tracepoint:raw_syscalls:sys_enter {
@[comm, pid] = count();
}
interval:s:5 { print(@, 10); clear(@); }
'
# 5. Tracer les connexions TCP sortantes
sudo bpftrace -e '
kprobe:tcp_connect {
$sk = (struct sock *)arg0;
$inet_family = $sk->__sk_common.skc_family;
if ($inet_family == 2) { // AF_INET
$daddr = ntop($sk->__sk_common.skc_daddr);
$dport = $sk->__sk_common.skc_dport;
printf("%-6d %-16s -> %s:%d\n", pid, comm, $daddr, $dport);
}
}
'
# 6. Mesurer la latence des requêtes DNS
sudo bpftrace -e '
uprobe:/lib/x86_64-linux-gnu/libc.so.6:getaddrinfo {
@start[tid] = nsecs;
@name[tid] = arg0;
}
uretprobe:/lib/x86_64-linux-gnu/libc.so.6:getaddrinfo /@start[tid]/ {
$latency_ms = (nsecs - @start[tid]) / 1000000;
printf("%-6d %-16s DNS lookup: %-30s %d ms\n",
pid, comm, str(@name[tid]), $latency_ms);
delete(@start[tid]);
delete(@name[tid]);
}
'
# 7. Script bpftrace complet : monitoring des processus qui consomment le plus de CPU
sudo bpftrace -e '
profile:hz:99 {
@cpu[comm, pid] = count();
}
interval:s:10 {
printf("\n--- Top CPU consumers (last 10s) ---\n");
print(@cpu, 10);
clear(@cpu);
}
'Script bpftrace avancé : analyse de latence complète
#!/usr/bin/env bpftrace
/*
* iolatency.bt - Analyse détaillée de la latence I/O
* Affiche un histogramme par type d'opération (R/W) et par disque
*/
BEGIN
{
printf("Tracing block I/O latency... Hit Ctrl-C to end.\n");
}
tracepoint:block:block_io_start
{
@start[args.sector] = nsecs;
@type[args.sector] = args.rwbs;
}
tracepoint:block:block_io_done
/@start[args.sector]/
{
$duration_us = (nsecs - @start[args.sector]) / 1000;
$type = @type[args.sector];
@latency_us[$type] = hist($duration_us);
@total_io[$type] = count();
@avg_us[$type] = avg($duration_us);
delete(@start[args.sector]);
delete(@type[args.sector]);
}
END
{
printf("\n=== I/O Latency Distribution (microseconds) ===\n");
print(@latency_us);
printf("\n=== Total I/O Count by Type ===\n");
print(@total_io);
printf("\n=== Average Latency (us) by Type ===\n");
print(@avg_us);
clear(@start);
clear(@type);
}Cilium : le networking eBPF pour Kubernetes
Cilium est le projet phare de l'écosystème eBPF pour Kubernetes. Développé par Isovalent (acquis par Cisco en 2024), Cilium est un CNI (Container Network Interface) qui remplace les composants réseau traditionnels de Kubernetes par des programmes eBPF hautement performants. Il est devenu le CNI par défaut de Google Kubernetes Engine (GKE) et est largement adopté par l'industrie.
Pourquoi Cilium remplace kube-proxy
Le composant kube-proxy de Kubernetes utilise traditionnellement iptables pour implémenter les Services Kubernetes. Or, iptables pose des problèmes fondamentaux à l'échelle :
- Complexité O(n) : chaque paquet doit traverser toutes les règles iptables linéairement. Avec 10 000 Services, cela signifie potentiellement 50 000+ règles
- Mises à jour coûteuses : chaque modification nécessite de réécrire l'ensemble des règles (opération non-atomique)
- Pas de visibilité : iptables ne fournit aucune métrique sur le trafic qui traverse les règles
- Pas de policies L7 : iptables opère aux couches 3/4 uniquement
Cilium remplace tout cela par des hash maps eBPF avec un lookup O(1), des mises à jour atomiques, une visibilité complète via Hubble, et des policies jusqu'à la couche 7 (HTTP, gRPC, Kafka, DNS).
Installation de Cilium
# Installer le CLI Cilium
CILIUM_CLI_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/cilium-cli/main/stable.txt)
CLI_ARCH=amd64
curl -L --fail --remote-name-all \
https://github.com/cilium/cilium-cli/releases/download/${CILIUM_CLI_VERSION}/cilium-linux-${CLI_ARCH}.tar.gz
sudo tar xzvfC cilium-linux-${CLI_ARCH}.tar.gz /usr/local/bin
rm cilium-linux-${CLI_ARCH}.tar.gz
# Installer Cilium sur un cluster Kubernetes (remplace kube-proxy)
cilium install --version 1.16.5 \
--set kubeProxyReplacement=true \
--set hubble.enabled=true \
--set hubble.relay.enabled=true \
--set hubble.ui.enabled=true
# Vérifier le statut
cilium status --wait
# Valider la connectivité
cilium connectivity testConfiguration Cilium avec Helm
# values-cilium.yaml - Configuration Cilium complète pour production
# Installer avec : helm install cilium cilium/cilium -n kube-system -f values-cilium.yaml
# === Remplacement de kube-proxy ===
kubeProxyReplacement: true
k8sServiceHost: "api.k8s.example.com"
k8sServicePort: "6443"
# === Tunnel mode ===
# "vxlan" pour la compatibilité, "disabled" pour le mode natif (meilleure perf)
tunnel: "disabled"
ipv4NativeRoutingCIDR: "10.0.0.0/8"
autoDirectNodeRoutes: true
# === IPAM ===
ipam:
mode: "kubernetes"
operator:
clusterPoolIPv4PodCIDRList:
- "10.244.0.0/16"
clusterPoolIPv4MaskSize: 24
# === eBPF ===
bpf:
masquerade: true
hostLegacyRouting: false
# Taille de la map pour le connection tracking
ctTcpMax: 524288
ctAnyMax: 262144
# Monitoring de la bande passante
monitorAggregation: medium
monitorInterval: "5s"
# === Load Balancing ===
loadBalancer:
algorithm: "maglev" # Consistent hashing pour un meilleur balancing
mode: "dsr" # Direct Server Return pour réduire la latence
acceleration: "native" # Utilise XDP pour le LB (best perf)
# === Hubble - Observabilité réseau ===
hubble:
enabled: true
metrics:
enabled:
- dns:query;ignoreAAAA
- drop
- tcp
- flow
- icmp
- httpV2:exemplars=true;labelsContext=source_ip,source_namespace,source_workload,destination_ip,destination_namespace,destination_workload,traffic_direction
serviceMonitor:
enabled: true # Pour Prometheus
relay:
enabled: true
resources:
limits:
cpu: "500m"
memory: "512Mi"
requests:
cpu: "100m"
memory: "128Mi"
ui:
enabled: true
ingress:
enabled: true
hosts:
- hubble.k8s.example.com
tls:
- secretName: hubble-tls
hosts:
- hubble.k8s.example.com
# === Network Policies ===
policyEnforcementMode: "default" # "default", "always", "never"
hostFirewall:
enabled: true # Policies sur les nœuds eux-mêmes
# === Bandwidth Manager ===
bandwidthManager:
enabled: true
bbr: true # Algorithme BBR de Google pour le TCP
# === Encryption ===
encryption:
enabled: true
type: "wireguard"
wireguard:
userspaceFallback: false
# === Operator ===
operator:
replicas: 2
resources:
limits:
cpu: "1000m"
memory: "1Gi"
requests:
cpu: "100m"
memory: "128Mi"
# === Agent ===
resources:
limits:
cpu: "2000m"
memory: "2Gi"
requests:
cpu: "200m"
memory: "256Mi"
# === Monitoring ===
prometheus:
enabled: true
serviceMonitor:
enabled: true
dashboards:
enabled: true
namespace: "monitoring"Network Policies L7 avec Cilium
L'un des avantages majeurs de Cilium est la possibilité de créer des network policies au niveau applicatif (L7). Voici un exemple :
# CiliumNetworkPolicy - Politique L7 HTTP
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "api-access-policy"
namespace: production
spec:
description: "Contrôle d'accès L7 pour l'API"
endpointSelector:
matchLabels:
app: api-server
ingress:
# Le frontend peut faire des GET/POST sur /api/v1/*
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: "GET"
path: "/api/v1/.*"
- method: "POST"
path: "/api/v1/orders"
headers:
- 'Content-Type: application/json'
# Le service de monitoring peut seulement lire /health et /metrics
- fromEndpoints:
- matchLabels:
app: monitoring
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: "GET"
path: "/health"
- method: "GET"
path: "/metrics"
egress:
# L'API peut accéder à la base de données PostgreSQL
- toEndpoints:
- matchLabels:
app: postgres
toPorts:
- ports:
- port: "5432"
protocol: TCP
# Et faire des requêtes DNS
- toEndpoints:
- matchLabels:
"k8s:io.kubernetes.pod.namespace": kube-system
k8s-app: kube-dns
toPorts:
- ports:
- port: "53"
protocol: ANY
rules:
dns:
- matchPattern: "*.production.svc.cluster.local"Hubble : l'observabilité réseau
# Installer le CLI Hubble
export HUBBLE_VERSION=$(curl -s https://raw.githubusercontent.com/cilium/hubble/master/stable.txt)
curl -L --fail --remote-name-all \
https://github.com/cilium/hubble/releases/download/$HUBBLE_VERSION/hubble-linux-amd64.tar.gz
sudo tar xzvfC hubble-linux-amd64.tar.gz /usr/local/bin
rm hubble-linux-amd64.tar.gz
# Port-forward le relay Hubble
cilium hubble port-forward &
# Observer les flux réseau en temps réel
hubble observe --namespace production
# Filtrer par verdict (DROPPED, FORWARDED, etc.)
hubble observe --verdict DROPPED --namespace production
# Filtrer par protocole HTTP et code de réponse
hubble observe --protocol http --http-status 500 --namespace production
# Voir les flux DNS
hubble observe --protocol dns --namespace production
# Exporter les métriques
hubble observe --output json | jq '.flow.source.namespace'Sécurité runtime avec Tetragon
Tetragon est un projet de sécurité runtime basé sur eBPF, également développé par Isovalent/Cisco. Contrairement à Falco qui détecte principalement les comportements suspects, Tetragon peut bloquer en temps réel les opérations dangereuses grâce à des programmes eBPF attachés aux hooks LSM et aux kprobes.
Caractéristiques de Tetragon
- Security observability : visibilité complète sur les processus, fichiers, réseau et appels système
- Runtime enforcement : blocage en temps réel des opérations non autorisées, directement dans le kernel
- Kubernetes-aware : enrichissement automatique avec les métadonnées Kubernetes (pod, namespace, labels)
- Overhead minimal : filtrage dans le kernel avant même que l'événement ne remonte en espace utilisateur
- Politiques déclaratives : TracingPolicy CRD pour définir ce qu'on observe et ce qu'on bloque
Installation de Tetragon
# Installation via Helm sur Kubernetes
helm repo add cilium https://helm.cilium.io
helm repo update
helm install tetragon cilium/tetragon \
-n kube-system \
--set tetragon.grpc.enabled=true \
--set tetragon.enableProcessCred=true \
--set tetragon.enableProcessNs=true
# Installer le CLI tetra
GOOS=$(go env GOOS)
GOARCH=$(go env GOARCH)
curl -L --remote-name-all \
https://github.com/cilium/tetragon/releases/latest/download/tetra-${GOOS}-${GOARCH}.tar.gz
sudo tar -C /usr/local/bin -xzvf tetra-${GOOS}-${GOARCH}.tar.gz
rm tetra-${GOOS}-${GOARCH}.tar.gz
# Observer les événements en temps réel
kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | tetra geteventsTracingPolicy : politiques de sécurité déclaratives
# Politique Tetragon : détecter et bloquer l'écriture dans /etc/passwd
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "block-etc-passwd-write"
spec:
kprobes:
- call: "security_file_permission"
syscall: false
args:
- index: 0
type: "file"
- index: 1
type: "int"
selectors:
- matchArgs:
- index: 0
operator: "Equal"
values:
- "/etc/passwd"
- "/etc/shadow"
- "/etc/sudoers"
- index: 1
operator: "Equal"
values:
- "2" # MAY_WRITE
matchActions:
- action: Sigkill # Tuer le processus qui tente l'écriture
---
# Politique Tetragon : détecter l'exécution de binaires suspects
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "detect-suspicious-binaries"
spec:
tracepoints:
- subsystem: "raw_syscalls"
event: "sys_enter"
args:
- index: 4
type: "syscall64"
selectors:
- matchArgs:
- index: 4
operator: "Equal"
values:
- "59" # SYS_execve
matchActions:
- action: Post
rateLimit: "1m"
rateLimitScope: process
---
# Politique Tetragon : empêcher les conteneurs de lancer un shell
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "block-shell-in-containers"
spec:
kprobes:
- call: "security_bprm_check"
syscall: false
args:
- index: 0
type: "linux_binprm"
selectors:
- matchArgs:
- index: 0
operator: "Equal"
values:
- "/bin/sh"
- "/bin/bash"
- "/bin/zsh"
- "/usr/bin/sh"
- "/usr/bin/bash"
matchNamespaces:
- namespace: Pid
operator: NotEqual
values:
- "host_ns" # Seulement dans les conteneurs
matchActions:
- action: Sigkill
message: "Shell execution blocked in container"Falco : la détection d'intrusions cloud native
Falco, projet de la CNCF, est un moteur de détection de menaces runtime qui utilise eBPF (ou un module kernel) pour surveiller les appels système et les événements Kubernetes. Il est complémentaire à Tetragon : là où Tetragon excelle dans l'enforcement, Falco brille dans la détection basée sur des règles riches et communautaires.
# Installation de Falco avec eBPF driver
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
helm install falco falcosecurity/falco \
--namespace falco --create-namespace \
--set driver.kind=ebpf \
--set falcosidekick.enabled=true \
--set falcosidekick.config.slack.webhookurl="https://hooks.slack.com/services/XXX"
# Vérifier que Falco fonctionne
kubectl logs -n falco -l app.kubernetes.io/name=falco# Règle Falco personnalisée
# falco-custom-rules.yaml
customRules:
custom-rules.yaml: |-
- rule: Detect Cryptocurrency Mining
desc: Detect attempts to mine cryptocurrency in containers
condition: >
spawned_process and
container and
(proc.name in (xmrig, minerd, minergate, cpuminer) or
proc.cmdline contains "stratum+tcp" or
proc.cmdline contains "stratum+ssl" or
proc.cmdline contains "coin" or
proc.cmdline contains "pool.minergate")
output: >
Cryptocurrency mining detected
(user=%user.name command=%proc.cmdline container=%container.name
image=%container.image.repository namespace=%k8s.ns.name
pod=%k8s.pod.name)
priority: CRITICAL
tags: [cryptomining, mitre_execution]
- rule: Sensitive File Access in Container
desc: Detect access to sensitive files within containers
condition: >
open_read and
container and
(fd.name startswith /etc/shadow or
fd.name startswith /etc/gshadow or
fd.name startswith /root/.ssh or
fd.name startswith /root/.bash_history)
output: >
Sensitive file accessed in container
(file=%fd.name user=%user.name command=%proc.cmdline
container=%container.name pod=%k8s.pod.name)
priority: WARNING
tags: [filesystem, mitre_credential_access]Pixie : l'observabilité auto-instrumentée pour Kubernetes
Pixie (projet CNCF, développé par New Relic) utilise eBPF pour fournir une observabilité automatique sans instrumentation des applications Kubernetes. Sans modifier une seule ligne de code, Pixie capture automatiquement :
- Les requêtes HTTP/gRPC/MySQL/PostgreSQL/Redis/Kafka avec leur contenu
- Les métriques CPU, mémoire, réseau par pod
- Les flamegraphs CPU en continu
- Les traces distribuées reconstruites automatiquement
# Installer Pixie
bash -c "$(curl -fsSL https://withpixie.ai/install.sh)"
# Déployer sur un cluster Kubernetes
px deploy
# Lancer une requête PxL (le langage de requête de Pixie)
px run px/http_data -- --start_time=-5m
# Voir les requêtes HTTP les plus lentes
px run px/http_data_filtered -- \
--start_time=-5m \
--namespace=production \
--min_latency=100
# Voir l'utilisation des ressources par pod
px run px/pod -- --namespace=productionPerformances : eBPF vs iptables
L'un des arguments les plus convaincants pour eBPF dans le networking est la différence de performance par rapport à iptables. Voici les résultats de benchmarks réalisés par Isovalent et la communauté :
| Métrique | iptables (kube-proxy) | Cilium eBPF | Amélioration |
|---|---|---|---|
| Latence du premier paquet (1k Services) | ~2.5 ms | ~0.3 ms | ~8x plus rapide |
| Latence du premier paquet (10k Services) | ~15 ms | ~0.3 ms | ~50x plus rapide |
| Temps de mise à jour (ajout d'un Service) | ~11 secondes (10k rules) | ~0.02 ms | ~500 000x plus rapide |
| Utilisation mémoire (10k Services) | ~250 MB | ~50 MB | 5x moins |
| Débit réseau (pps, XDP mode) | ~2M pps | ~14M pps | 7x plus rapide |
| CPU overhead par paquet | Élevé (linéaire) | Constant (O(1)) | Scalabilité supérieure |
La différence est particulièrement frappante à l'échelle. Un cluster avec 10 000 Services et 100 000 endpoints verra iptables s'écrouler sous le poids de centaines de milliers de règles, tandis qu'eBPF maintiendra des performances constantes grâce à ses hash maps O(1).
Adoption par l'industrie
eBPF n'est plus une technologie expérimentale. En 2025-2026, les plus grandes entreprises technologiques l'utilisent massivement en production :
Meta (Facebook)
Meta est l'un des contributeurs majeurs d'eBPF. L'entreprise utilise eBPF pour :
- Katran : load balancer L4 basé sur XDP, traitant des milliards de requêtes par jour
- Networking : remplacement quasi complet d'iptables dans leur infrastructure
- Observabilité : profiling CPU continu sur l'ensemble de leur flotte de serveurs
Google utilise eBPF dans GKE (Google Kubernetes Engine) via Cilium comme CNI par défaut, et pour le profiling continu dans ses datacenters. Le projet gVisor intègre également des composants eBPF.
Netflix
Netflix, à travers le travail de Brendan Gregg, a été un pionnier de l'utilisation d'eBPF pour l'observabilité. Ils utilisent BCC et bpftrace pour le debugging de performance sur leur infrastructure de streaming.
Cloudflare
Cloudflare utilise eBPF/XDP pour :
- DDoS mitigation : filtrage des attaques directement dans le driver réseau avec XDP
- Load balancing : distribution du trafic à la périphérie
- Flowtrackd : suivi avancé des connexions TCP
Microsoft
Microsoft a porté eBPF sur Windows avec le projet eBPF for Windows, et l'utilise dans Azure pour le networking et la sécurité. C'est un signal fort de l'universalité d'eBPF au-delà de Linux.
Autres adoptions notables
- Datadog : utilise eBPF pour le monitoring réseau et la sécurité (Cloud Workload Security)
- Grafana : Beyla, un outil d'auto-instrumentation basé sur eBPF
- Alibaba, Tencent, ByteDance : utilisation massive dans leurs infrastructures cloud
- Red Hat / RHEL : intégration d'eBPF comme technologie de première classe
Limites et prérequis d'eBPF
Malgré ses avantages considérables, eBPF a des limites qu'il est important de connaître :
Prérequis kernel
- Version minimale du kernel : Linux 4.9+ pour les fonctionnalités de base, mais 5.10+ est recommandé pour les fonctionnalités modernes (BTF, boucles bornées, CO-RE). Pour Cilium, le minimum est 4.19.57 mais 5.10+ est fortement recommandé
- CONFIG_BPF=y : le kernel doit être compilé avec le support BPF
- CONFIG_BPF_SYSCALL=y : pour charger des programmes depuis l'espace utilisateur
- CONFIG_BPF_JIT=y : pour la compilation JIT (performances)
- CONFIG_DEBUG_INFO_BTF=y : pour la portabilité CO-RE (Compile Once, Run Everywhere)
Limitations techniques
- Taille de la pile : limitée à 512 octets, ce qui contraint les structures de données locales
- Complexité du vérifieur : le vérifieur peut rejeter des programmes valides s'ils sont trop complexes ou si les preuves de sûreté ne sont pas évidentes. Le debugging des rejets du vérifieur est parfois frustrant
- Pas de boucles arbitraires : les boucles doivent être bornées (le compilateur doit pouvoir prouver qu'elles terminent)
- Pas d'allocation dynamique : pas de malloc dans les programmes eBPF
- Appels de fonctions limités : seules les helper functions exposées par le kernel sont disponibles (bien que les BPF subprograms permettent des appels entre programmes eBPF)
- Privilèges : charger des programmes eBPF nécessite généralement CAP_BPF ou root (les programmes non-privilégiés sont possibles mais limités)
Courbe d'apprentissage
- Écrire des programmes eBPF en C bas niveau est complexe (bien que libbpf et libbpf-rs simplifient considérablement)
- Comprendre les interactions avec le kernel requiert une connaissance approfondie de Linux
- Le debugging est plus difficile que pour du code userspace classique
- Les outils haut niveau (bpftrace, Cilium, Falco) abstraient cette complexité pour la majorité des cas d'usage
Sécurité du mécanisme lui-même
- Des vulnérabilités dans le vérifieur eBPF ont été découvertes par le passé (CVE-2021-3490, CVE-2021-31440). Le vérifieur est un composant critique qui fait l'objet d'audits et de fuzzing intensifs
- Les programmes eBPF s'exécutent avec les privilèges du kernel : un programme malveillant autorisé pourrait théoriquement être dangereux. D'où l'importance des prérequis de privilèges pour charger des programmes
Développer avec eBPF : l'écosystème de développement
libbpf et CO-RE (Compile Once, Run Everywhere)
L'approche moderne pour développer des programmes eBPF repose sur libbpf et CO-RE. CO-RE permet de compiler un programme eBPF une seule fois et de l'exécuter sur différentes versions du kernel, grâce à BTF (BPF Type Format) qui fournit les informations de type du kernel.
# Vérifier le support BTF de votre kernel
ls -la /sys/kernel/btf/vmlinux
# Installer les outils de développement eBPF
sudo apt-get install libbpf-dev clang llvm libelf-dev
# Compiler un programme eBPF avec CO-RE
clang -target bpf -D__TARGET_ARCH_x86 -O2 -g \
-c my_program.bpf.c -o my_program.bpf.o
# Générer le skeleton C
bpftool gen skeleton my_program.bpf.o > my_program.skel.hLangages et frameworks
- C + libbpf : l'approche standard, la plus performante et portable
- Rust + Aya : framework Rust pour eBPF, de plus en plus populaire en 2025
- Go + cilium/ebpf : bibliothèque Go pour charger et interagir avec des programmes eBPF
- Python + BCC : pour le prototypage rapide et les scripts d'observabilité
- bpftrace : langage de scripting dédié au traçage
Exemple en Python avec BCC
#!/usr/bin/env python3
"""
Tracer les appels à execve() et afficher les commandes exécutées.
Utilise BCC (BPF Compiler Collection) pour Python.
"""
from bcc import BPF
from bcc.utils import printb
import ctypes
# Programme eBPF en C, compilé et chargé par BCC
bpf_program = """
#include
#include
#include
#define ARGSIZE 256
#define MAXARG 20
struct event_t {
u32 pid;
u32 ppid;
u32 uid;
char comm[TASK_COMM_LEN];
char filename[ARGSIZE];
int retval;
};
BPF_PERF_OUTPUT(events);
TRACEPOINT_PROBE(syscalls, sys_enter_execve) {
struct event_t event = {};
struct task_struct *task;
event.pid = bpf_get_current_pid_tgid() >> 32;
event.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
task = (struct task_struct *)bpf_get_current_task();
event.ppid = task->real_parent->tgid;
bpf_get_current_comm(&event.comm, sizeof(event.comm));
bpf_probe_read_user_str(&event.filename, sizeof(event.filename),
args->filename);
events.perf_submit(args, &event, sizeof(event));
return 0;
}
"""
# Charger le programme eBPF
b = BPF(text=bpf_program)
# Callback pour les événements
def print_event(cpu, data, size):
event = b["events"].event(data)
printb(b"%-6d %-6d %-6d %-16s %s" % (
event.pid,
event.ppid,
event.uid,
event.comm,
event.filename,
))
# Header
print("%-6s %-6s %-6s %-16s %s" % ("PID", "PPID", "UID", "COMM", "FILENAME"))
# Ouvrir le buffer d'événements
b["events"].open_perf_buffer(print_event)
# Boucle principale
while True:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
print("\nDetaching...")
exit()Bonnes pratiques pour adopter eBPF
Par où commencer
- Utilisez les outils existants : ne réinventez pas la roue. bpftrace, BCC tools, Cilium, Falco, Tetragon couvrent 95 % des cas d'usage
- Commencez par l'observabilité : c'est le cas d'usage le moins risqué et le plus immédiatement utile. Installez bpftrace et explorez votre système
- Migrez vers Cilium progressivement : si vous utilisez Kubernetes, migrez votre CNI vers Cilium pour bénéficier du networking eBPF
- Ajoutez la sécurité : une fois familiarisé, déployez Falco pour la détection et Tetragon pour l'enforcement
Vérifier la compatibilité de votre système
# Vérifier la version du kernel
uname -r
# Vérifier le support eBPF
sudo bpftool feature probe kernel
# Vérifier la disponibilité de BTF
ls -la /sys/kernel/btf/vmlinux
# Tester avec un programme simple
sudo bpftrace -e 'BEGIN { printf("eBPF works!\n"); exit(); }'
# Vérifier les capabilities nécessaires
capsh --print | grep bpfConsidérations en production
- Monitoring de l'overhead : même si eBPF est performant, surveillez l'impact de vos programmes sur le CPU et la mémoire
- Gestion des versions kernel : testez vos programmes eBPF sur toutes les versions de kernel de votre flotte
- Utilisation de CO-RE : préférez CO-RE pour la portabilité entre versions de kernel
- Alerting sur les erreurs du vérifieur : loguez les échecs de chargement de programmes eBPF
- Dimensionnement des maps : les maps eBPF consomment de la mémoire kernel. Dimensionnez-les en fonction de vos besoins réels
L'avenir d'eBPF
L'écosystème eBPF continue d'évoluer rapidement en 2025-2026 :
- eBPF for Windows : Microsoft porte activement eBPF sur Windows, ouvrant la voie à une portabilité multi-OS
- BPF tokens : nouveau mécanisme pour déléguer les privilèges eBPF de manière granulaire (kernel 6.9+)
- Arènes BPF : mémoire partagée entre programmes eBPF et espace utilisateur pour des performances accrues
- eBPF dans le hardware : des NIC (cartes réseau) intelligentes commencent à exécuter des programmes eBPF directement dans le matériel
- Standardisation : la Fondation eBPF travaille sur la standardisation de l'ABI et des formats
- Service mesh sans sidecar : Cilium Service Mesh élimine le besoin de proxies sidecar, réduisant la consommation de ressources de 50 % ou plus
Conclusion
eBPF représente une transformation fondamentale de la façon dont nous interagissons avec le noyau Linux. En rendant le kernel programmable de manière sûre et performante, il a ouvert la voie à une nouvelle génération d'outils qui redéfinissent l'observabilité, le networking et la sécurité des systèmes modernes.
L'analogie avec JavaScript et le web est pertinente : de même que JavaScript a transformé les pages web statiques en applications dynamiques, eBPF transforme le noyau Linux d'un bloc monolithique en une plateforme programmable. Et comme pour le web, ce sont les frameworks et les outils construits sur cette fondation — Cilium, Falco, Tetragon, bpftrace — qui rendent cette puissance accessible à tous.
Si vous gérez une infrastructure Linux, que ce soit un serveur unique ou des milliers de nœuds Kubernetes, eBPF n'est plus une technologie optionnelle. C'est un avantage compétitif en termes de performance, de sécurité et d'observabilité. Commencez par installer bpftrace sur un serveur de développement, explorez les BCC tools, et vous comprendrez rapidement pourquoi l'industrie entière se tourne vers eBPF.
Pour aller plus loin : le site ebpf.io est le point d'entrée officiel de l'écosystème eBPF. Le livre "BPF Performance Tools" de Brendan Gregg (Addison-Wesley) est la référence pour l'observabilité. Et le repository Cilium sur GitHub est un excellent exemple de projet eBPF de production.





