

Introduction : Pourquoi les inventaires statiques ne suffisent plus
Dans un monde où l'infrastructure cloud évolue en permanence — des instances qui apparaissent et disparaissent selon la charge, des conteneurs éphémères, des groupes d'auto-scaling — maintenir un fichier d'inventaire statique Ansible devient rapidement un cauchemar opérationnel. Chaque nouvelle machine déployée doit être ajoutée manuellement, chaque suppression doit être répercutée, et le moindre oubli peut entraîner des échecs de déploiement ou, pire encore, des configurations appliquées à des machines fantômes.
Les inventaires dynamiques Ansible résolvent ce problème fondamental en interrogeant directement vos fournisseurs cloud (AWS, Azure, GCP) pour construire automatiquement la liste des hôtes cibles. Plus besoin de synchroniser manuellement : votre inventaire reflète toujours l'état réel de votre infrastructure.
Architecture en un coup d'œil
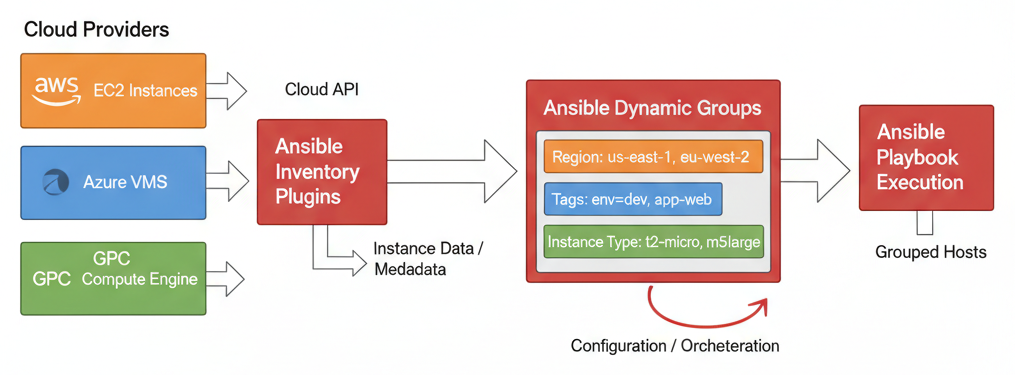
Dans cet article, nous allons explorer en profondeur le fonctionnement des inventaires dynamiques, configurer des plugins pour les trois principaux clouds, et découvrir les bonnes pratiques pour les utiliser en production.
Les limites des inventaires statiques
Un inventaire statique Ansible se présente généralement sous la forme d'un fichier INI ou YAML listant explicitement les hôtes et les groupes :
# inventory/hosts.yml - Inventaire statique classique
all:
children:
webservers:
hosts:
web01.example.com:
ansible_host: 10.0.1.10
web02.example.com:
ansible_host: 10.0.1.11
web03.example.com:
ansible_host: 10.0.1.12
databases:
hosts:
db01.example.com:
ansible_host: 10.0.2.10
db02.example.com:
ansible_host: 10.0.2.11Ce modèle fonctionne très bien pour des infrastructures stables et de petite taille. Mais il révèle ses limites dès que l'on passe à l'échelle :
- Maintenance manuelle fastidieuse : chaque changement d'infrastructure nécessite une mise à jour du fichier d'inventaire.
- Risque de désynchronisation : l'inventaire peut ne plus refléter l'état réel de l'infrastructure, entraînant des erreurs silencieuses.
- Incompatibilité avec l'auto-scaling : les groupes d'auto-scaling créent et détruisent des instances en permanence, rendant tout suivi manuel impossible.
- Absence de métadonnées dynamiques : les tags cloud, les types d'instances et les régions ne sont pas automatiquement exploitables.
- Difficulté de collaboration : dans une équipe, plusieurs personnes modifient le même fichier, créant des conflits Git et des incohérences.
- Scalabilité limitée : gérer des centaines ou des milliers d'hôtes dans un fichier texte devient ingérable.
Qu'est-ce qu'un inventaire dynamique ?
Un inventaire dynamique est un mécanisme qui permet à Ansible d'obtenir la liste des hôtes et leurs métadonnées à la volée, au moment de l'exécution. Au lieu de lire un fichier statique, Ansible exécute un plugin d'inventaire (ou un script externe) qui interroge une source de données externe — un cloud provider, une base de données CMDB, un service de découverte de services, etc. — et retourne la liste des hôtes au format JSON.
Le processus est le suivant :
- Ansible détecte le type de source d'inventaire (fichier statique, plugin, ou script).
- Si c'est un plugin d'inventaire, Ansible charge le plugin correspondant et lui passe la configuration.
- Le plugin interroge l'API du fournisseur cloud (par exemple, l'API EC2 d'AWS).
- Le plugin retourne la liste des hôtes avec leurs groupes et variables.
- Ansible utilise cette liste exactement comme il utiliserait un inventaire statique.
L'avantage majeur est que l'inventaire est toujours à jour : chaque exécution d'Ansible récupère l'état actuel de votre infrastructure.
Les plugins d'inventaire Ansible : concept fondamental
Depuis Ansible 2.4, la méthode recommandée pour utiliser des inventaires dynamiques est de passer par les plugins d'inventaire. Ils remplacent les anciens scripts d'inventaire externes et offrent plusieurs avantages :
- Intégration native : les plugins sont inclus dans les collections Ansible officielles.
- Configuration déclarative : la configuration se fait via des fichiers YAML, cohérents avec le reste de l'écosystème Ansible.
- Cache intégré : les plugins supportent nativement le cache pour éviter de surcharger les API cloud.
- Composition avancée : les directives
keyed_groups,composeetgroupspermettent de créer des groupes et des variables calculées.
Pour activer les plugins d'inventaire, vous devez les déclarer dans votre fichier ansible.cfg :
# ansible.cfg
[inventory]
enable_plugins = amazon.aws.aws_ec2, azure.azcollection.azure_rm, google.cloud.gcp_compute, yaml, ini, autoLes collections correspondantes doivent également être installées :
# Installation des collections cloud
ansible-galaxy collection install amazon.aws
ansible-galaxy collection install azure.azcollection
ansible-galaxy collection install google.cloud
# Vérifier les collections installées
ansible-galaxy collection list | grep -E "amazon|azure|google"Plugin AWS EC2 : Configuration complète
Prérequis
Avant de configurer le plugin AWS EC2, assurez-vous que les dépendances Python sont installées et que vos credentials AWS sont configurées :
# Installation des dépendances Python
pip install boto3 botocore
# Configuration des credentials AWS (méthode recommandée)
export AWS_ACCESS_KEY_ID="votre_access_key"
export AWS_SECRET_ACCESS_KEY="votre_secret_key"
export AWS_DEFAULT_REGION="eu-west-3"
# Ou via le fichier ~/.aws/credentials
aws configureFichier de configuration de base
Le fichier d'inventaire dynamique AWS EC2 doit obligatoirement se terminer par aws_ec2.yml ou aws_ec2.yaml pour être reconnu par le plugin :
# inventory/aws_ec2.yml
plugin: amazon.aws.aws_ec2
# Régions à scanner
regions:
- eu-west-3
- eu-west-1
- us-east-1
# Filtres pour limiter les résultats
filters:
# Uniquement les instances en cours d'exécution
instance-state-name: running
# Filtrer par tag
"tag:Environment":
- production
- staging
# Utiliser l'adresse IP privée pour la connexion
hostnames:
- private-ip-address
# Création de groupes dynamiques basés sur les attributs EC2
keyed_groups:
# Grouper par région
- key: placement.region
prefix: region
separator: "_"
# Grouper par type d'instance
- key: instance_type
prefix: type
separator: "_"
# Grouper par tag Environment
- key: tags.Environment
prefix: env
separator: "_"
# Grouper par tag Role
- key: tags.Role
prefix: role
separator: "_"
# Grouper par VPC
- key: vpc_id
prefix: vpc
separator: "_"
# Variables composées (calculées à partir des attributs)
compose:
# Définir ansible_host avec l'IP privée
ansible_host: private_ip_address
# Ajouter des variables personnalisées
instance_name: tags.Name | default("sans_nom")
ec2_region: placement.region
# Groupes conditionnels
groups:
# Créer un groupe "large_instances" pour les instances avec beaucoup de CPU
large_instances: instance_type.startswith("m5.2x") or instance_type.startswith("c5.2x")
# Groupe pour les instances avec un volume EBS chiffré
production: "'production' in (tags.Environment | default(''))"Configuration avancée avec cache
Pour éviter de faire trop d'appels API à AWS (ce qui peut être lent et coûteux), activez le cache :
# inventory/aws_ec2_cached.yml
plugin: amazon.aws.aws_ec2
regions:
- eu-west-3
filters:
instance-state-name: running
# Configuration du cache
cache: true
cache_plugin: jsonfile
cache_timeout: 300 # 5 minutes en secondes
cache_connection: /tmp/ansible_aws_inventory_cache
cache_prefix: aws_ec2
keyed_groups:
- key: placement.region
prefix: region
- key: tags.Environment
prefix: env
- key: tags.Role
prefix: role
- key: instance_type
prefix: type
hostnames:
- tag:Name
- private-ip-address
compose:
ansible_host: private_ip_address
ansible_user: "'ec2-user'"
ansible_ssh_private_key_file: "'~/.ssh/aws-prod.pem'"Filtres avancés par tags
Les filtres AWS EC2 sont extrêmement puissants. Voici quelques exemples courants :
# inventory/aws_ec2_filtered.yml
plugin: amazon.aws.aws_ec2
regions:
- eu-west-3
# Filtres multiples (ET logique entre les filtres)
filters:
instance-state-name: running
"tag:Environment": production
"tag:ManagedBy": ansible
"tag:Project":
- codeclan
- api-backend
instance-type:
- t3.medium
- t3.large
- m5.large
# Exclure certaines instances via include_filters
# (disponible dans les versions récentes du plugin)
exclude_filters:
- "tag:AnsibleIgnore":
- "true"
keyed_groups:
- key: tags.Project
prefix: project
- key: tags.Role
prefix: role
- key: tags.Team
prefix: team
compose:
ansible_host: private_ip_address
ansible_user: tags.get('AnsibleUser', 'ec2-user')
deployment_slot: tags.DeploymentSlot | default('blue')Plugin Azure Resource Manager
Prérequis Azure
# Installation des dépendances
pip install azure-identity azure-mgmt-compute azure-mgmt-network azure-mgmt-resource
# Configuration de l'authentification (Service Principal)
export AZURE_SUBSCRIPTION_ID="votre_subscription_id"
export AZURE_CLIENT_ID="votre_client_id"
export AZURE_SECRET="votre_client_secret"
export AZURE_TENANT="votre_tenant_id"Fichier de configuration Azure
Le fichier doit se terminer par azure_rm.yml ou azure_rm.yaml :
# inventory/azure_rm.yml
plugin: azure.azcollection.azure_rm
# Authentification (peut aussi être via variables d'environnement)
auth_source: auto
# Inclure uniquement certains resource groups
include_vm_resource_groups:
- rg-production
- rg-staging
- rg-codeclan
# Exclure des resource groups
exclude_vm_resource_groups:
- rg-development
- rg-sandbox
# Utiliser l'IP privée pour la connexion
default_host_filters: []
use_contrib_script_compatible_sanitization: true
# Filtres conditionnels
conditional_groups:
# Créer des groupes basés sur des conditions
linux_vms: "'linux' in image.offer | lower"
windows_vms: "'windows' in image.offer | lower"
running_vms: "powerstate == 'running'"
# Groupes basés sur les clés (tags, location, etc.)
keyed_groups:
# Grouper par localisation Azure
- key: location
prefix: location
separator: "_"
# Grouper par tag environment
- key: tags.environment | default('untagged')
prefix: env
separator: "_"
# Grouper par tag role
- key: tags.role | default('unknown')
prefix: role
separator: "_"
# Grouper par taille de VM
- key: virtual_machine_size
prefix: size
separator: "_"
# Grouper par resource group
- key: resource_group
prefix: rg
separator: "_"
# Grouper par OS
- key: image.offer
prefix: os
separator: "_"
# Variables composées
compose:
ansible_host: private_ipv4_addresses[0] | default(public_ipv4_addresses[0], true)
ansible_user: tags.ansible_user | default('azureuser')
vm_size: virtual_machine_size
azure_location: location
azure_rg: resource_group
# Hostnames personnalisés
hostnames:
- name
- default # nom de la ressource Azure
# Cache pour limiter les appels API
cache: true
cache_plugin: jsonfile
cache_timeout: 600
cache_connection: /tmp/ansible_azure_inventory_cacheConfiguration multi-souscription
# inventory/azure_rm_multi.yml
plugin: azure.azcollection.azure_rm
auth_source: auto
# Scanner plusieurs souscriptions Azure
include_vm_resource_groups:
- "*" # Tous les resource groups
# Filtrer par tags uniquement
conditional_groups:
managed_by_ansible: "'ansible' in (tags.managed_by | default('') | lower)"
production_tier: "'production' in (tags.environment | default('') | lower)"
keyed_groups:
- key: tags.environment | default('no_env')
prefix: env
- key: tags.application | default('no_app')
prefix: app
- key: location
prefix: loc
compose:
ansible_host: private_ipv4_addresses[0]
ansible_user: "'azureuser'"
ansible_become: truePlugin Google Cloud Platform (GCP)
Prérequis GCP
# Installation des dépendances
pip install google-auth google-api-python-client
# Configuration de l'authentification
# Option 1 : Via un fichier de compte de service
export GCP_SERVICE_ACCOUNT_FILE="/chemin/vers/service-account.json"
# Option 2 : Via gcloud CLI
gcloud auth application-default login
# Option 3 : Variable d'environnement avec le contenu JSON
export GCP_SERVICE_ACCOUNT_CONTENTS='{ ... }'Fichier de configuration GCP
Le fichier doit se terminer par gcp_compute.yml ou gcp.yml :
# inventory/gcp_compute.yml
plugin: google.cloud.gcp_compute
# Projets GCP à scanner
projects:
- codeclan-production
- codeclan-staging
# Régions à inclure (laisser vide pour toutes)
zones: []
# Filtres GCP (syntaxe de l'API Google Compute)
filters:
- status = RUNNING
- "labels.managed_by = ansible"
# Compte de service pour l'authentification
auth_kind: serviceaccount
service_account_file: /etc/ansible/gcp-service-account.json
# Groupes basés sur les clés
keyed_groups:
# Grouper par zone
- key: zone
prefix: zone
separator: "_"
# Grouper par type de machine
- key: machineType
prefix: machine
separator: "_"
# Grouper par label environment
- key: labels.environment | default('unlabeled')
prefix: env
separator: "_"
# Grouper par label role
- key: labels.role | default('unknown')
prefix: role
separator: "_"
# Grouper par réseau
- key: networkInterfaces[0].network | basename
prefix: network
separator: "_"
# Grouper par projet
- key: project
prefix: project
separator: "_"
# Grouper par status
- key: status | lower
prefix: status
separator: "_"
# Variables composées
compose:
# Utiliser l'IP interne par défaut
ansible_host: networkInterfaces[0].networkIP
# IP externe si disponible
public_ip: networkInterfaces[0].accessConfigs[0].natIP | default('none')
# Nom d'instance
instance_name: name
# Zone courte (ex: europe-west1-b)
gcp_zone: zone | basename
# Région (dérivée de la zone)
gcp_region: zone | basename | regex_replace('-[a-z]$', '')
# Utilisateur SSH
ansible_user: "'debian'"
# Groupes conditionnels
groups:
has_public_ip: "networkInterfaces[0].accessConfigs is defined"
preemptible: "scheduling.preemptible | default(false)"
europe: "'europe' in zone"
us: "'us-' in zone"
# Hostnames
hostnames:
- name
- public_ip
- private_ip
# Cache
cache: true
cache_plugin: jsonfile
cache_timeout: 300
cache_connection: /tmp/ansible_gcp_inventory_cacheConfiguration GCP multi-projets avancée
# inventory/gcp_compute_advanced.yml
plugin: google.cloud.gcp_compute
projects:
- codeclan-prod
- codeclan-staging
- codeclan-dev
# Limiter à certaines zones européennes
zones:
- europe-west1-b
- europe-west1-c
- europe-west1-d
- europe-west9-a
- europe-west9-b
filters:
- status = RUNNING
auth_kind: serviceaccount
service_account_file: "{{ lookup('env', 'GCP_SERVICE_ACCOUNT_FILE') }}"
keyed_groups:
- key: labels.environment
prefix: env
- key: labels.role
prefix: role
- key: labels.team
prefix: team
- key: machineType | basename
prefix: type
- key: zone | basename | regex_replace('-[a-z]$', '')
prefix: region
compose:
ansible_host: networkInterfaces[0].networkIP
ansible_user: labels.ssh_user | default('ansible')
ansible_become: true
gcp_project: project
gcp_zone: zone | basename
disk_size_gb: disks[0].diskSizeGb | default(0) | intLes directives keyed_groups, compose et groups en détail
Ces trois directives sont le coeur de la puissance des plugins d'inventaire Ansible. Elles sont communes à tous les plugins et permettent une organisation fine de vos hôtes.
keyed_groups : grouper automatiquement
La directive keyed_groups crée des groupes Ansible à partir des attributs des hôtes :
keyed_groups:
# Syntaxe complète
- key: attribut_de_lhote # Expression Jinja2 pour extraire la valeur
prefix: prefixe_du_groupe # Préfixe ajouté au nom du groupe
separator: "_" # Séparateur entre préfixe et valeur
default_value: "inconnu" # Valeur par défaut si l'attribut est absent
parent_group: "tous_mes_hotes" # Groupe parent optionnel
# Exemples concrets
- key: tags.Environment
prefix: env
# Résultat : env_production, env_staging, env_development
- key: instance_type
prefix: ""
separator: ""
# Résultat : t3.micro, m5.large (nom brut sans préfixe)
- key: placement.availability_zone
prefix: az
# Résultat : az_eu_west_3a, az_eu_west_3bcompose : créer des variables calculées
La directive compose permet de définir des variables d'hôte à partir d'expressions Jinja2 :
compose:
# Variable simple
ansible_host: private_ip_address
# Variable avec valeur par défaut
env: tags.Environment | default('dev')
# Concaténation
fqdn: name ~ '.example.com'
# Condition
ansible_user: "'admin' if tags.OS == 'ubuntu' else 'ec2-user'"
# Calcul
is_large: instance_type.startswith('m5') or instance_type.startswith('c5')groups : groupes conditionnels
La directive groups crée des groupes basés sur des conditions booléennes :
groups:
# Groupe basé sur un tag
webservers: "'web' in (tags.Role | default(''))"
# Groupe basé sur le type d'instance
gpu_instances: "instance_type.startswith('p3') or instance_type.startswith('g4')"
# Groupe basé sur la région
eu_hosts: "'eu-' in placement.region"
# Groupe toujours vrai (tous les hôtes)
all_managed: trueTester et valider votre inventaire dynamique
Avant d'utiliser votre inventaire dynamique dans des playbooks, il est essentiel de le tester. Ansible fournit la commande ansible-inventory spécialement conçue pour cela.
Commandes de test essentielles
# Afficher l'arborescence des groupes et hôtes
ansible-inventory -i inventory/aws_ec2.yml --graph
# Exemple de sortie :
# @all:
# |--@env_production:
# | |--10.0.1.15
# | |--10.0.1.22
# |--@env_staging:
# | |--10.0.2.10
# |--@region_eu_west_3:
# | |--10.0.1.15
# | |--10.0.1.22
# | |--10.0.2.10
# |--@role_webserver:
# | |--10.0.1.15
# | |--10.0.1.22
# |--@role_database:
# | |--10.0.2.10
# Afficher l'inventaire complet en JSON
ansible-inventory -i inventory/aws_ec2.yml --list
# Afficher les détails d'un hôte spécifique
ansible-inventory -i inventory/aws_ec2.yml --host 10.0.1.15
# Afficher l'inventaire au format YAML (plus lisible)
ansible-inventory -i inventory/aws_ec2.yml --list --yaml
# Tester la connectivité avec un module ping
ansible -i inventory/aws_ec2.yml all -m ping --limit "env_production"
# Lister uniquement les hôtes d'un groupe
ansible -i inventory/aws_ec2.yml env_production --list-hosts
# Combiner avec un filtre de pattern
ansible -i inventory/aws_ec2.yml 'env_production:&role_webserver' --list-hostsDébogage en cas de problème
# Mode verbose pour voir les appels API
ansible-inventory -i inventory/aws_ec2.yml --list -vvv
# Vérifier que le plugin est bien chargé
ansible-doc -t inventory -l | grep aws_ec2
# Tester les credentials
python3 -c "import boto3; ec2 = boto3.client('ec2', region_name='eu-west-3'); print(ec2.describe_instances())"
# Vider le cache si les résultats semblent obsolètes
rm -rf /tmp/ansible_aws_inventory_cache/*Combiner inventaires statiques et dynamiques
Dans la pratique, il est courant de combiner des sources d'inventaire statiques et dynamiques. Ansible permet cela nativement en pointant vers un répertoire contenant plusieurs fichiers d'inventaire.
Structure recommandée
# Structure du répertoire d'inventaire
inventory/
├── 00_static_hosts.yml # Inventaire statique (serveurs on-premise)
├── 10_aws_ec2.yml # Inventaire dynamique AWS
├── 20_azure_rm.yml # Inventaire dynamique Azure
├── 30_gcp_compute.yml # Inventaire dynamique GCP
├── group_vars/
│ ├── all.yml # Variables pour tous les hôtes
│ ├── env_production.yml # Variables pour le groupe env_production
│ ├── env_staging.yml # Variables pour le groupe env_staging
│ └── webservers.yml # Variables pour le groupe webservers
└── host_vars/
└── bastion01.yml # Variables spécifiques au bastionLes fichiers sont traités par ordre alphabétique. Le préfixe numérique permet de contrôler cet ordre et ainsi la priorité des variables.
Exemple d'inventaire statique pour les serveurs on-premise
# inventory/00_static_hosts.yml
all:
children:
onpremise:
children:
bastions:
hosts:
bastion01:
ansible_host: 192.168.1.10
ansible_user: admin
network_devices:
hosts:
switch01:
ansible_host: 192.168.1.1
ansible_network_os: cisco.ios.ios
ansible_connection: network_cli
firewall01:
ansible_host: 192.168.1.2
ansible_network_os: paloaltonetworks.panos
legacy_servers:
hosts:
legacy-app01:
ansible_host: 192.168.10.50
ansible_user: root
ansible_python_interpreter: /usr/bin/python2Utilisation combinée
# Pointer vers le répertoire entier
ansible-inventory -i inventory/ --graph
# Le résultat combine tous les inventaires :
# @all:
# |--@bastions: (statique)
# | |--bastion01
# |--@env_production: (dynamique AWS)
# | |--10.0.1.15
# |--@location_westeurope: (dynamique Azure)
# | |--vm-web-01
# |--@zone_europe_west1_b: (dynamique GCP)
# | |--gcp-app-01
# Exécuter un playbook avec l'inventaire combiné
ansible-playbook -i inventory/ site.ymlConfiguration dans ansible.cfg
# ansible.cfg
[defaults]
# Pointer vers le répertoire d'inventaire par défaut
inventory = ./inventory/
# Plugins d'inventaire activés
[inventory]
enable_plugins = amazon.aws.aws_ec2, azure.azcollection.azure_rm, google.cloud.gcp_compute, yaml, iniÉcrire un script d'inventaire custom
Parfois, vous avez besoin d'un inventaire dynamique qui interroge une source de données spécifique (CMDB, base de données interne, API propriétaire). Dans ce cas, vous pouvez écrire votre propre script d'inventaire.
Règles d'un script d'inventaire
Un script d'inventaire doit respecter les conventions suivantes :
- Être exécutable (
chmod +x). - Accepter l'argument
--listet retourner un JSON avec tous les groupes et hôtes. - Accepter l'argument
--host <hostname>et retourner les variables de cet hôte. - La sortie doit être du JSON valide sur stdout.
Exemple : script d'inventaire interrogeant une API REST
#!/usr/bin/env python3
"""
Script d'inventaire dynamique Ansible
Interroge une API CMDB interne pour récupérer les hôtes
"""
import argparse
import json
import sys
try:
import requests
except ImportError:
print("Le module 'requests' est requis : pip install requests", file=sys.stderr)
sys.exit(1)
CMDB_API_URL = "https://cmdb.example.com/api/v1"
CMDB_API_TOKEN = "votre_token_api"
def get_hosts_from_cmdb():
"""Récupère tous les hôtes depuis la CMDB."""
headers = {
"Authorization": f"Bearer {CMDB_API_TOKEN}",
"Content-Type": "application/json"
}
try:
response = requests.get(
f"{CMDB_API_URL}/servers",
headers=headers,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"Erreur lors de l'appel CMDB : {e}", file=sys.stderr)
return []
def build_inventory():
"""Construit l'inventaire Ansible à partir des données CMDB."""
hosts = get_hosts_from_cmdb()
inventory = {
"_meta": {
"hostvars": {}
},
"all": {
"children": []
}
}
# Organiser les hôtes par groupe
groups = {}
for host in hosts:
hostname = host["hostname"]
ip = host["ip_address"]
role = host.get("role", "ungrouped")
environment = host.get("environment", "unknown")
os_type = host.get("os", "linux")
# Variables de l'hôte
inventory["_meta"]["hostvars"][hostname] = {
"ansible_host": ip,
"ansible_user": host.get("ssh_user", "ansible"),
"environment": environment,
"os_type": os_type,
"datacenter": host.get("datacenter", "dc1"),
"cmdb_id": host.get("id")
}
# Grouper par rôle
role_group = f"role_{role}"
if role_group not in groups:
groups[role_group] = []
groups[role_group].append(hostname)
# Grouper par environnement
env_group = f"env_{environment}"
if env_group not in groups:
groups[env_group] = []
groups[env_group].append(hostname)
# Grouper par OS
os_group = f"os_{os_type}"
if os_group not in groups:
groups[os_group] = []
groups[os_group].append(hostname)
# Ajouter les groupes à l'inventaire
for group_name, group_hosts in groups.items():
inventory[group_name] = {
"hosts": group_hosts
}
inventory["all"]["children"].append(group_name)
return inventory
def get_host_vars(hostname):
"""Retourne les variables d'un hôte spécifique."""
inventory = build_inventory()
return inventory["_meta"]["hostvars"].get(hostname, {})
def main():
parser = argparse.ArgumentParser(
description="Script d'inventaire dynamique Ansible"
)
parser.add_argument(
"--list",
action="store_true",
help="Liste tous les groupes et hôtes"
)
parser.add_argument(
"--host",
type=str,
help="Retourne les variables d'un hôte"
)
args = parser.parse_args()
if args.list:
inventory = build_inventory()
print(json.dumps(inventory, indent=2))
elif args.host:
hostvars = get_host_vars(args.host)
print(json.dumps(hostvars, indent=2))
else:
parser.print_help()
sys.exit(1)
if __name__ == "__main__":
main()Utilisation du script custom
# Rendre le script exécutable
chmod +x inventory/cmdb_inventory.py
# Tester le script
./inventory/cmdb_inventory.py --list | python3 -m json.tool
# Utiliser avec Ansible
ansible-inventory -i inventory/cmdb_inventory.py --graph
ansible-playbook -i inventory/cmdb_inventory.py site.ymlBonnes pratiques pour les inventaires dynamiques
1. Toujours activer le cache en production
Les appels API sont lents et limités en débit. Configurez toujours le cache avec un timeout raisonnable :
# Recommandation : cache de 5 à 10 minutes
cache: true
cache_plugin: jsonfile
cache_timeout: 300
cache_connection: /tmp/ansible_inventory_cache2. Filtrer au maximum côté API
Plutôt que de récupérer toutes les instances et de filtrer ensuite, utilisez les filtres natifs du plugin pour réduire le volume de données retournées par l'API :
# Bon : filtre côté API
filters:
instance-state-name: running
"tag:ManagedBy": ansible
# Éviter : récupérer tout puis filtrer avec groups/keyed_groups3. Utiliser des tags/labels cohérents
La qualité de votre inventaire dynamique dépend directement de la qualité du tagging de vos ressources cloud. Définissez une convention de nommage et appliquez-la systématiquement :
# Convention de tags recommandée
# Environment: production | staging | development
# Role: webserver | database | cache | worker | bastion
# Project: nom_du_projet
# Team: nom_de_equipe
# ManagedBy: ansible | terraform | manual
# OS: ubuntu | centos | amazon-linux4. Séparer les inventaires par environnement
# Structure recommandée
inventories/
├── production/
│ ├── aws_ec2.yml
│ ├── azure_rm.yml
│ └── group_vars/
├── staging/
│ ├── aws_ec2.yml
│ └── group_vars/
└── development/
├── aws_ec2.yml
└── group_vars/# Déployer en production
ansible-playbook -i inventories/production/ site.yml
# Déployer en staging
ansible-playbook -i inventories/staging/ site.yml5. Sécuriser les credentials
Ne jamais mettre de credentials en dur dans les fichiers d'inventaire. Utilisez toujours des variables d'environnement, des fichiers de credentials séparés, ou un gestionnaire de secrets comme HashiCorp Vault ou AWS Secrets Manager.
# Bon : utiliser des variables d'environnement
auth_kind: serviceaccount
service_account_file: "{{ lookup('env', 'GCP_SERVICE_ACCOUNT_FILE') }}"
# Mauvais : credentials en dur
# service_account_file: /home/user/ma-cle-secrete.json6. Documenter vos fichiers d'inventaire
# inventory/aws_ec2.yml
#
# Inventaire dynamique AWS EC2 - Production EU
# Maintenu par : Équipe DevOps
# Dernière révision : 2026-03-07
#
# Ce fichier découvre automatiquement les instances EC2
# dans la région eu-west-3 avec le tag ManagedBy=ansible
#
# Prérequis :
# - Collection amazon.aws installée
# - Variables AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY définies
# - pip install boto3 botocore
#
plugin: amazon.aws.aws_ec2
regions:
- eu-west-37. Tester avant chaque mise en production
# Script de validation d'inventaire
#!/bin/bash
set -e
echo "=== Validation de l'inventaire dynamique ==="
# Vérifier que l'inventaire se charge sans erreur
echo "[1/4] Chargement de l'inventaire..."
ansible-inventory -i inventory/ --list > /dev/null 2>&1
echo " OK"
# Vérifier que les groupes attendus existent
echo "[2/4] Vérification des groupes..."
GROUPS=$(ansible-inventory -i inventory/ --graph)
for group in env_production env_staging role_webserver role_database; do
if echo "$GROUPS" | grep -q "@${group}"; then
echo " Groupe $group : OK"
else
echo " Groupe $group : MANQUANT"
exit 1
fi
done
# Vérifier la connectivité
echo "[3/4] Test de connectivité (ping)..."
ansible -i inventory/ all -m ping --limit "env_staging" -o
# Vérifier le nombre d'hôtes
echo "[4/4] Comptage des hôtes..."
HOST_COUNT=$(ansible -i inventory/ all --list-hosts | grep -c "hosts")
echo " Nombre total d'hôtes : $HOST_COUNT"
echo "=== Validation terminée avec succès ==="Cas d'usage avancé : inventaire multi-cloud
Pour les organisations qui utilisent plusieurs clouds simultanément, voici une configuration complète permettant de gérer un inventaire multi-cloud unifié :
# inventory/group_vars/all.yml
# Variables communes à tous les hôtes, quel que soit le cloud
---
ansible_python_interpreter: auto_silent
ansible_become: true
ntp_servers:
- 0.pool.ntp.org
- 1.pool.ntp.org
monitoring_endpoint: "https://monitoring.example.com/api"
log_aggregator: "logs.example.com:5044"# inventory/group_vars/env_production.yml
# Variables spécifiques à la production
---
deploy_env: production
debug_mode: false
log_level: warn
backup_enabled: true
backup_retention_days: 30
ssl_enforce: trueAvec cette structure, vous pouvez cibler vos playbooks de manière très granulaire :
# Tous les serveurs web en production, tous clouds confondus
ansible-playbook -i inventory/ webservers.yml --limit "env_production:&role_webserver"
# Uniquement les serveurs AWS en staging
ansible-playbook -i inventory/ site.yml --limit "env_staging:®ion_eu_west_3"
# Les bases de données Azure en production
ansible-playbook -i inventory/ databases.yml --limit "env_production:&role_database:&location_westeurope"Conclusion
Les inventaires dynamiques Ansible sont un composant indispensable de toute infrastructure cloud moderne. En remplaçant les fichiers statiques sujets aux erreurs par des requêtes automatiques vers les API de vos fournisseurs cloud, vous gagnez en fiabilité, en maintenabilité et en réactivité.
Les points essentiels à retenir :
- Les plugins d'inventaire (aws_ec2, azure_rm, gcp_compute) sont la méthode moderne et recommandée.
- Les directives keyed_groups, compose et groups permettent une organisation fine et automatique de vos hôtes.
- Le cache est indispensable en production pour limiter les appels API.
- Un tagging cohérent de vos ressources cloud est la clé d'un inventaire dynamique efficace.
- La combinaison statique/dynamique permet de couvrir tous les cas de figure (cloud + on-premise).
- Pour les sources non standard, un script d'inventaire custom en Python offre une flexibilité totale.
Dans le prochain article de notre série, nous comparerons Ansible avec ses principaux concurrents — SaltStack et Puppet — pour vous aider à choisir l'outil de configuration management le plus adapté à vos besoins.





