

L'un des principes fondamentaux de l'Infrastructure as Code est la réutilisabilité. Écrire du code Terraform en dur avec des valeurs figées, c'est comme écrire un programme sans paramètres : ça fonctionne une fois, mais c'est impossible à maintenir ou à adapter. C'est là qu'interviennent les variables, les outputs et les locals de Terraform. Ces mécanismes transforment vos configurations statiques en templates dynamiques, capables de s'adapter à n'importe quel environnement — développement, staging ou production — sans modifier une seule ligne de code HCL.
Dans cet article, nous allons explorer en profondeur le système de variables de Terraform. Vous apprendrez à déclarer des variables d'entrée avec des types, des validations et des valeurs par défaut, à utiliser les fichiers .tfvars et les variables d'environnement, à exposer des informations via les outputs, et à organiser le tout selon les bonnes pratiques. Préparez-vous à rendre votre code Terraform véritablement flexible et professionnel.
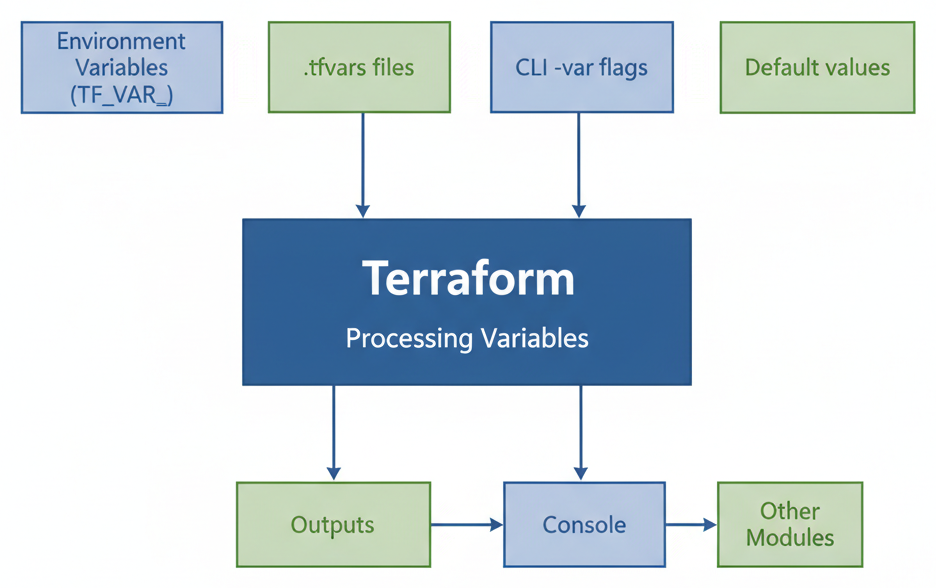
Flux des Variables Terraform
Les Variables d'Entrée (Input Variables)
Déclarer une variable simple
Une variable d'entrée se déclare avec le bloc variable. À sa forme la plus simple, elle ne nécessite qu'un nom :
variable "region" {}
Cependant, en pratique, vous voudrez toujours fournir au minimum une description et un type. Voici une déclaration plus complète :
variable "region" {
description = "La région AWS dans laquelle déployer les ressources"
type = string
default = "eu-west-3"
}
Les attributs principaux d'une variable sont :
- description : une explication lisible de la variable, affichée lors du
terraform planet dans la documentation générée. - type : le type de données attendu (nous y reviendrons en détail).
- default : la valeur par défaut. Si elle est définie, la variable devient optionnelle.
- sensitive : un booléen qui masque la valeur dans les logs.
- nullable : indique si la variable peut accepter
nullcomme valeur. - validation : un ou plusieurs blocs de validation personnalisée.
Les types de variables
Terraform supporte un système de types riche qui vous permet de contraindre précisément les valeurs acceptées. Voici les types disponibles :
Types primitifs :
# String - chaîne de caractères
variable "environment" {
description = "Nom de l'environnement"
type = string
default = "development"
}
# Number - nombre entier ou décimal
variable "instance_count" {
description = "Nombre d'instances à créer"
type = number
default = 2
}
# Bool - booléen
variable "enable_monitoring" {
description = "Activer le monitoring CloudWatch"
type = bool
default = true
}
Types complexes — collections :
# List - liste ordonnée d'éléments du même type
variable "availability_zones" {
description = "Liste des zones de disponibilité"
type = list(string)
default = ["eu-west-3a", "eu-west-3b", "eu-west-3c"]
}
# Map - paires clé/valeur
variable "tags" {
description = "Tags à appliquer aux ressources"
type = map(string)
default = {
Project = "mon-projet"
ManagedBy = "terraform"
}
}
# Set - ensemble non ordonné d'éléments uniques
variable "allowed_ports" {
description = "Ports autorisés dans le security group"
type = set(number)
default = [22, 80, 443]
}
Types complexes — structurels :
# Object - structure avec des attributs nommés et typés
variable "database_config" {
description = "Configuration de la base de données"
type = object({
engine = string
engine_version = string
instance_class = string
allocated_storage = number
multi_az = bool
})
default = {
engine = "postgres"
engine_version = "14.3"
instance_class = "db.t3.micro"
allocated_storage = 20
multi_az = false
}
}
# Tuple - liste ordonnée avec des types différents par position
variable "ingress_rule" {
description = "Règle d'entrée : [port, protocole, cidr]"
type = tuple([number, string, string])
default = [443, "tcp", "0.0.0.0/0"]
}
Le type object est particulièrement puissant pour regrouper des configurations liées en une seule variable cohérente, plutôt que de multiplier les variables individuelles.
Validation des variables
Depuis Terraform 0.13, vous pouvez ajouter des blocs validation à vos variables pour vérifier que les valeurs fournies respectent vos contraintes métier. C'est un filet de sécurité essentiel :
variable "environment" {
description = "Environnement de déploiement"
type = string
validation {
condition = contains(["development", "staging", "production"], var.environment)
error_message = "L'environnement doit être 'development', 'staging' ou 'production'."
}
}
variable "instance_type" {
description = "Type d'instance EC2"
type = string
default = "t3.micro"
validation {
condition = can(regex("^t3\\.", var.instance_type))
error_message = "Seules les instances de la famille t3 sont autorisées."
}
}
variable "cidr_block" {
description = "Bloc CIDR du VPC"
type = string
default = "10.0.0.0/16"
validation {
condition = can(cidrhost(var.cidr_block, 0))
error_message = "La valeur doit être un bloc CIDR valide (ex: 10.0.0.0/16)."
}
}
Vous pouvez même combiner plusieurs blocs validation sur une même variable pour vérifier différentes contraintes :
variable "project_name" {
description = "Nom du projet"
type = string
validation {
condition = length(var.project_name) >= 3
error_message = "Le nom du projet doit contenir au moins 3 caractères."
}
validation {
condition = length(var.project_name) <= 24
error_message = "Le nom du projet ne doit pas dépasser 24 caractères."
}
validation {
condition = can(regex("^[a-z][a-z0-9-]*$", var.project_name))
error_message = "Le nom du projet doit commencer par une lettre minuscule et ne contenir que des lettres minuscules, des chiffres et des tirets."
}
}
Variables sensibles
Certaines variables contiennent des informations confidentielles : mots de passe, clés API, tokens. Terraform permet de les marquer comme sensitive pour éviter qu'elles apparaissent dans les logs et les sorties du plan :
variable "db_password" {
description = "Mot de passe de la base de données"
type = string
sensitive = true
validation {
condition = length(var.db_password) >= 12
error_message = "Le mot de passe doit contenir au moins 12 caractères."
}
}
variable "api_key" {
description = "Clé API du service externe"
type = string
sensitive = true
}
Lorsque vous exécutez terraform plan ou terraform apply, les valeurs sensibles sont remplacées par (sensitive value) dans toute la sortie. Attention toutefois : la valeur reste stockée en clair dans le fichier state. La sécurisation du state est donc cruciale (nous y reviendrons dans un prochain article).
Fournir des Valeurs aux Variables
Terraform offre plusieurs mécanismes pour passer des valeurs aux variables, avec un ordre de priorité bien défini.
Fichiers .tfvars
La méthode la plus courante est d'utiliser des fichiers .tfvars. Ces fichiers contiennent les valeurs assignées aux variables :
# terraform.tfvars
region = "eu-west-3"
environment = "production"
instance_count = 3
instance_type = "t3.medium"
tags = {
Project = "mon-application"
Team = "platform"
ManagedBy = "terraform"
}
availability_zones = [
"eu-west-3a",
"eu-west-3b",
"eu-west-3c"
]
database_config = {
engine = "postgres"
engine_version = "14.3"
instance_class = "db.r5.large"
allocated_storage = 100
multi_az = true
}
Par convention, Terraform charge automatiquement les fichiers nommés terraform.tfvars ou *.auto.tfvars. Pour tout autre nom, vous devez le spécifier explicitement :
# Chargement automatique
terraform apply # charge terraform.tfvars et *.auto.tfvars
# Chargement explicite
terraform apply -var-file="production.tfvars"
terraform apply -var-file="environments/staging.tfvars"
Cette mécanique permet de gérer facilement plusieurs environnements :
project/
├── main.tf
├── variables.tf
├── outputs.tf
├── environments/
│ ├── dev.tfvars
│ ├── staging.tfvars
│ └── production.tfvars
# Déployer en dev
terraform plan -var-file="environments/dev.tfvars"
# Déployer en production
terraform plan -var-file="environments/production.tfvars"
Variables d'environnement TF_VAR_
Terraform lit automatiquement les variables d'environnement préfixées par TF_VAR_. Le nom de la variable d'environnement correspond au nom de la variable Terraform en majuscules après le préfixe :
# Définir des variables via l'environnement
export TF_VAR_region="eu-west-3"
export TF_VAR_environment="staging"
export TF_VAR_instance_count=2
export TF_VAR_db_password="MonSuperMotDePasse123!"
# Puis exécuter terraform normalement
terraform plan
terraform apply
Cette méthode est particulièrement adaptée pour les variables sensibles dans les pipelines CI/CD. Au lieu de stocker un mot de passe dans un fichier, vous le passez via une variable d'environnement injectée par votre système de secrets (Vault, AWS Secrets Manager, etc.).
Ligne de commande avec -var
Vous pouvez aussi passer des valeurs directement en ligne de commande :
terraform apply \
-var="region=eu-west-3" \
-var="environment=production" \
-var='tags={"Project":"web","Team":"devops"}'
Ordre de priorité
Lorsque plusieurs sources fournissent la même variable, Terraform applique l'ordre de priorité suivant (du moins prioritaire au plus prioritaire) :
- Valeur par défaut dans la déclaration
variable - Variables d'environnement
TF_VAR_* - Fichier
terraform.tfvars(chargé automatiquement) - Fichiers
*.auto.tfvars(chargés automatiquement, par ordre alphabétique) - Fichiers spécifiés avec
-var-file(dans l'ordre de la ligne de commande) - Options
-varen ligne de commande (dans l'ordre)
Cet ordre est déterministe : la dernière valeur trouvée l'emporte toujours.
Les Outputs (Valeurs de Sortie)
Déclarer et utiliser des outputs
Les outputs permettent d'exposer des informations sur votre infrastructure après un terraform apply. Ils sont déclarés avec le bloc output :
output "vpc_id" {
description = "L'identifiant du VPC créé"
value = aws_vpc.main.id
}
output "instance_public_ip" {
description = "L'adresse IP publique de l'instance EC2"
value = aws_instance.web.public_ip
}
output "database_endpoint" {
description = "Le point de terminaison de la base de données RDS"
value = aws_db_instance.main.endpoint
}
output "load_balancer_dns" {
description = "Le nom DNS du load balancer"
value = aws_lb.main.dns_name
}
Après un terraform apply, ces valeurs sont affichées dans le terminal :
Apply complete! Resources: 12 added, 0 changed, 0 destroyed.
Outputs:
database_endpoint = "mydb.abc123.eu-west-3.rds.amazonaws.com:5432"
instance_public_ip = "52.47.123.45"
load_balancer_dns = "my-lb-1234567890.eu-west-3.elb.amazonaws.com"
vpc_id = "vpc-0abc123def456"
Vous pouvez également consulter les outputs à tout moment avec :
# Afficher tous les outputs
terraform output
# Afficher un output spécifique
terraform output vpc_id
# Afficher un output en format JSON (utile pour le scripting)
terraform output -json
Outputs sensibles
Comme les variables, les outputs peuvent être marqués comme sensibles :
output "db_password" {
description = "Le mot de passe généré pour la base de données"
value = random_password.db.result
sensitive = true
}
output "tls_private_key" {
description = "La clé privée TLS"
value = tls_private_key.main.private_key_pem
sensitive = true
}
Un output sensible n'est pas affiché dans le terminal, mais reste accessible via terraform output -json ou terraform output db_password.
Outputs et dépendances entre modules
L'un des usages les plus importants des outputs est le partage de données entre modules. Lorsque vous structurez votre code en modules (ce que nous verrons dans un futur article), les outputs du module enfant sont accessibles par le module parent :
# Module réseau - outputs.tf
output "vpc_id" {
value = aws_vpc.main.id
}
output "public_subnet_ids" {
value = aws_subnet.public[*].id
}
# Module applicatif - main.tf
module "network" {
source = "./modules/network"
# ...
}
resource "aws_instance" "web" {
subnet_id = module.network.public_subnet_ids[0]
vpc_security_group_ids = [aws_security_group.web.id]
# ...
}
Les outputs créent ainsi un contrat d'interface clair entre les différents composants de votre infrastructure.
Outputs avec des expressions complexes
Les outputs peuvent contenir des expressions élaborées pour formater ou transformer les données exposées :
output "instance_info" {
description = "Informations détaillées sur les instances"
value = {
for instance in aws_instance.web :
instance.tags["Name"] => {
id = instance.id
public_ip = instance.public_ip
private_ip = instance.private_ip
az = instance.availability_zone
}
}
}
output "connection_strings" {
description = "Chaînes de connexion formatées"
value = {
postgres = "postgresql://${var.db_user}:****@${aws_db_instance.main.endpoint}/${var.db_name}"
redis = "redis://${aws_elasticache_cluster.main.cache_nodes[0].address}:6379"
}
}
Les Locals (Variables Locales)
Les locals sont des variables internes à votre configuration. Contrairement aux variables d'entrée, elles ne sont pas exposées à l'utilisateur. Elles servent à simplifier et centraliser des expressions complexes ou des valeurs calculées :
locals {
# Valeurs calculées
project_prefix = "${var.project_name}-${var.environment}"
# Tags communs à toutes les ressources
common_tags = {
Project = var.project_name
Environment = var.environment
ManagedBy = "terraform"
Region = var.region
CreatedAt = timestamp()
}
# Logique conditionnelle centralisée
is_production = var.environment == "production"
instance_type = local.is_production ? "t3.large" : "t3.micro"
instance_count = local.is_production ? 3 : 1
multi_az = local.is_production ? true : false
enable_backups = local.is_production ? true : false
# Calculs de sous-réseaux
azs = ["${var.region}a", "${var.region}b", "${var.region}c"]
public_subnets = [
for i, az in local.azs :
cidrsubnet(var.vpc_cidr, 8, i)
]
private_subnets = [
for i, az in local.azs :
cidrsubnet(var.vpc_cidr, 8, i + 10)
]
}
Ensuite, vous référencez ces locals avec le préfixe local. (au singulier) :
resource "aws_instance" "web" {
count = local.instance_count
instance_type = local.instance_type
ami = data.aws_ami.amazon_linux.id
tags = merge(local.common_tags, {
Name = "${local.project_prefix}-web-${count.index + 1}"
Role = "web-server"
})
}
resource "aws_vpc" "main" {
cidr_block = var.vpc_cidr
tags = merge(local.common_tags, {
Name = "${local.project_prefix}-vpc"
})
}
Les locals sont particulièrement utiles pour :
- Éviter de répéter des expressions complexes à plusieurs endroits
- Centraliser la logique conditionnelle liée à l'environnement
- Créer des tags cohérents appliqués à toutes les ressources
- Préparer des données transformées (calculs CIDR, formatage de noms, etc.)
Bonnes Pratiques d'Organisation des Variables
Structure de fichiers recommandée
Par convention, les variables, outputs et locals sont organisés dans des fichiers dédiés :
project/
├── main.tf # Ressources principales
├── variables.tf # Déclarations de variables
├── outputs.tf # Déclarations des outputs
├── locals.tf # Variables locales
├── providers.tf # Configuration des providers
├── versions.tf # Contraintes de versions
├── terraform.tfvars # Valeurs par défaut (non commité si sensible)
├── environments/
│ ├── dev.tfvars
│ ├── staging.tfvars
│ └── prod.tfvars
└── .gitignore # Exclure *.tfvars sensibles
Conventions de nommage
Adoptez des conventions de nommage claires et cohérentes :
# BON : noms descriptifs avec des underscores
variable "vpc_cidr_block" {}
variable "enable_dns_support" {}
variable "max_instance_count" {}
# MAUVAIS : noms ambigus ou incohérents
variable "cidr" {} # Trop vague
variable "enableDns" {} # camelCase non conventionnel
variable "cnt" {} # Abréviation obscure
Grouper les variables par catégorie
Dans votre fichier variables.tf, regroupez les variables par thème avec des commentaires :
# ==============================================================================
# Variables Générales
# ==============================================================================
variable "project_name" {
description = "Nom du projet utilisé pour le nommage des ressources"
type = string
validation {
condition = can(regex("^[a-z][a-z0-9-]{2,23}$", var.project_name))
error_message = "Le nom du projet doit faire entre 3 et 24 caractères (minuscules, chiffres, tirets)."
}
}
variable "environment" {
description = "Environnement de déploiement"
type = string
validation {
condition = contains(["dev", "staging", "prod"], var.environment)
error_message = "L'environnement doit être 'dev', 'staging' ou 'prod'."
}
}
variable "region" {
description = "Région AWS cible"
type = string
default = "eu-west-3"
}
# ==============================================================================
# Variables Réseau
# ==============================================================================
variable "vpc_cidr" {
description = "Bloc CIDR pour le VPC"
type = string
default = "10.0.0.0/16"
validation {
condition = can(cidrhost(var.vpc_cidr, 0))
error_message = "Veuillez fournir un bloc CIDR valide."
}
}
variable "enable_nat_gateway" {
description = "Créer une NAT Gateway pour les sous-réseaux privés"
type = bool
default = false
}
# ==============================================================================
# Variables Compute
# ==============================================================================
variable "instance_type" {
description = "Type d'instance EC2"
type = string
default = "t3.micro"
}
variable "instance_count" {
description = "Nombre d'instances à déployer"
type = number
default = 1
validation {
condition = var.instance_count >= 1 && var.instance_count <= 10
error_message = "Le nombre d'instances doit être compris entre 1 et 10."
}
}
# ==============================================================================
# Variables Base de Données
# ==============================================================================
variable "db_config" {
description = "Configuration de la base de données RDS"
type = object({
engine = string
engine_version = string
instance_class = string
allocated_storage = number
multi_az = bool
backup_retention = number
})
default = {
engine = "postgres"
engine_version = "14.3"
instance_class = "db.t3.micro"
allocated_storage = 20
multi_az = false
backup_retention = 7
}
}
variable "db_password" {
description = "Mot de passe administrateur de la base de données"
type = string
sensitive = true
validation {
condition = length(var.db_password) >= 16
error_message = "Le mot de passe doit contenir au moins 16 caractères pour la sécurité."
}
}
Documenter et valider systématiquement
Chaque variable devrait avoir :
- Une description claire et précise
- Un type explicite (même si Terraform peut inférer)
- Une valeur par défaut raisonnable quand c'est pertinent
- Des validations pour les contraintes métier
Le fichier .gitignore pour les variables
Ne commettez jamais de fichiers contenant des valeurs sensibles. Voici un .gitignore type pour un projet Terraform :
# Fichiers Terraform locaux
.terraform/
*.tfstate
*.tfstate.backup
# Fichiers de variables potentiellement sensibles
# Commiter uniquement les .tfvars non sensibles
secret.tfvars
*.secret.tfvars
# Fichiers de plan
*.tfplan
# Override files
override.tf
override.tf.json
*_override.tf
*_override.tf.json
# Crash logs
crash.log
crash.*.log
Exemple Pratique Complet
Pour conclure avec un exemple concret, voici une configuration complète qui illustre l'utilisation combinée des variables, locals et outputs pour un déploiement web :
# variables.tf
variable "project_name" {
description = "Nom du projet"
type = string
validation {
condition = can(regex("^[a-z][a-z0-9-]{2,23}$", var.project_name))
error_message = "Nom invalide : 3-24 caractères, minuscules, chiffres et tirets."
}
}
variable "environment" {
description = "Environnement cible"
type = string
validation {
condition = contains(["dev", "staging", "prod"], var.environment)
error_message = "Environnement invalide."
}
}
variable "web_config" {
description = "Configuration du serveur web"
type = object({
instance_type = string
min_size = number
max_size = number
port = number
})
default = {
instance_type = "t3.micro"
min_size = 1
max_size = 3
port = 8080
}
}
# locals.tf
locals {
name_prefix = "${var.project_name}-${var.environment}"
common_tags = {
Project = var.project_name
Environment = var.environment
ManagedBy = "terraform"
}
is_prod = var.environment == "prod"
web_min_size = local.is_prod ? max(var.web_config.min_size, 2) : 1
web_max_size = local.is_prod ? var.web_config.max_size : 2
}
# outputs.tf
output "deployment_summary" {
description = "Résumé du déploiement"
value = {
project = var.project_name
environment = var.environment
region = var.region
is_prod = local.is_prod
web_scaling = "${local.web_min_size}-${local.web_max_size} instances"
}
}
Conclusion
Les variables, outputs et locals constituent le socle de tout code Terraform professionnel. En maîtrisant ces mécanismes, vous transformez des configurations rigides en templates réutilisables, capables de s'adapter à tous vos environnements.
Retenez ces principes essentiels :
- Typez et validez systématiquement vos variables d'entrée
- Utilisez les locals pour centraliser la logique et éviter les répétitions
- Exposez via les outputs les informations nécessaires aux autres modules et aux utilisateurs
- Protégez les données sensibles avec l'attribut
sensitiveet les variables d'environnement - Organisez vos fichiers selon les conventions de la communauté Terraform
Dans le prochain article, nous mettrons ces connaissances en pratique en déployant vos premières ressources cloud sur AWS avec Terraform. Vous verrez comment créer un VPC, des instances EC2 et des buckets S3 en utilisant les variables et bonnes pratiques que nous venons d'apprendre. Restez connectés !





